

Getting the right Machine Learning models to the right places at the right time is difficult at scale. Machine Learning Operations (MLOps) solves that problem, but many need help making it simple. MLOps is a set of tools and practices which help ensure that the development and release of ML models is orderly, repeatable, and scalable. This is an oversimplification, but roughly speaking it ensures that:
- Developers have the right ML tools and environments to build with.
- The right models are put into the right places at the right times.
- Performance of the models (outcomes, regulatory, and policy) is understood over time.
- Updates to models can be created and deployed effectively.
All of these are simple, intuitive ideas—there is nothing magical about any of the components. The challenge comes in making these things happen at scale. That is, if you have a few models, manually tracking and deploying them isn’t so hard. However, when you have dozens or hundreds of models, all being created and maintained by different people, this starts to become difficult. Fortunately, there is precedent for solving this problem: DevOps (a portmanteau of software Development and IT Operations).
DevOps is a formalization of the practices that software engineers use to write and deploy software. To maximize learning cycles, development teams often strive for continuous integration and continuous deployment (CI/CD)—that is, pushing code changes into the field as soon as they are made and tested. This is done by programmatically linking commits from the code repository with testing, building, and deployment tools so that the software gets to all the locations in the correct form for each location.
The exact tools and processes used vary from company to company but, suffice it to say, it relies on a pipeline of many software tools configured to work together—each one doing a specific task within the larger DevOps flow. If that sounds natural to you, then you’re probably someone who would appreciate MLOps. If this sounds like a mysterious pile of jargon, then hang in there, as there is hope.
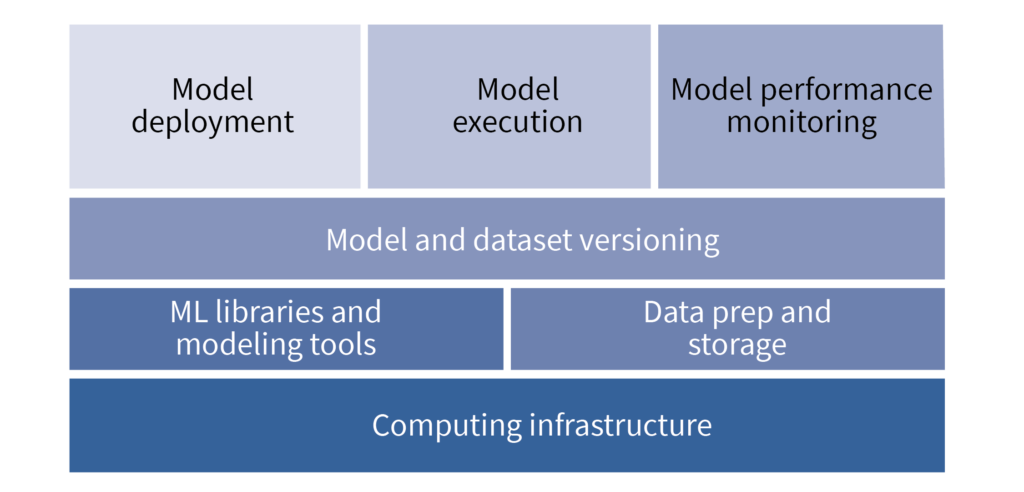 Figure 1: A high-level picture of the components of MLOps
Figure 1: A high-level picture of the components of MLOps
There are, broadly speaking, two ways to think about ML models: 1) as a type of software development, and 2), as part of a packaged application.
The Developer-Centric Approach
In the developer-centric case, you get a team of developers (data scientists) to write the code (models) and release it using a standard DevOps (MLOps) flow. This works great when you have people who are familiar with setting up, running, and working within a highly code-driven environment. Many large organizations can afford to set up and maintain these groups. Despite Microsoft’s assertion that, “Every business will become a software business,” I think it is safe to say that most organizations have neither the resources nor expertise required to set up and run a system like this.
It would be a significant stretch to ask your senior metallurgists, reliability engineers, or even your typical plant IT engineer to spec out, provision, configure, operate, and maintain an MLOps pipeline—even if it resides in the cloud. In the more common case of limited software development expertise and resources, ML deployment cannot follow a full DevOps-inspired model (that would be ideal, but it is not practical). Instead, a more black-box, packaged approach is required. That is, the goals that MLOps sets out to facilitate are still important, but they have to be met with a form factor that lets non-software engineering types do the work.
The Application-Centric Approach
In the application-centric case, details of the MLOps work are hidden from the end-user. This comes with tradeoffs in terms of flexibility. For example, the application may not support a particular, cutting-edge ML algorithm or the versioning system may not have the structure recommended by a consultant. However, in the spirit of not letting the perfect be the enemy of the good, I think it is reasonable to say that 1,000 configuration options are too many when even 10 options cannot be effectively managed.
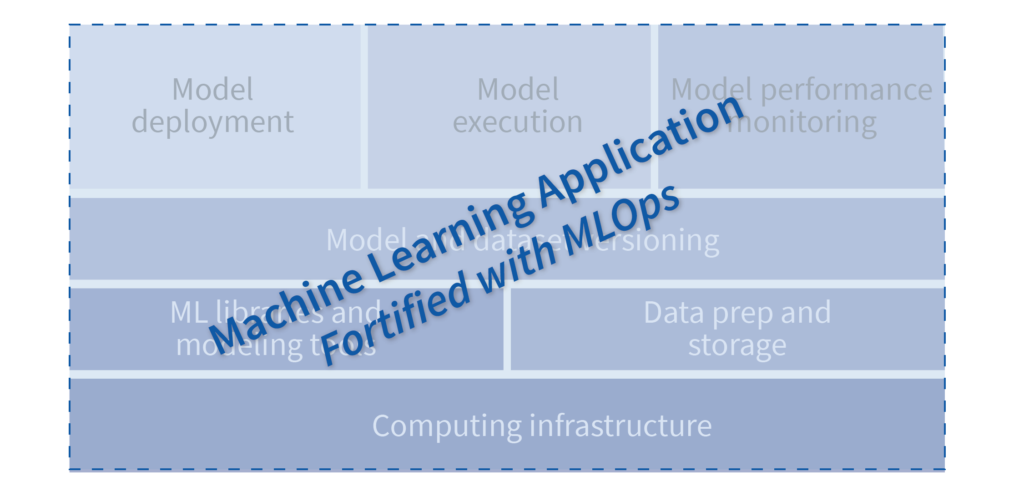 Figure 2: Moving MLOps inside the black box of an application
Figure 2: Moving MLOps inside the black box of an application
Which One Would Work Best for You?
What does putting MLOps into practice then mean? In the first case, it means a DevOps-inspired suite that is operated by a dedicated team of specialists. It gives the most flexibility and most capability at the cost of expertise required to run the MLOps system—not a small thing but the most powerful thing for those who can manage it.
In the second case, it means running an application that contains the most important elements of MLOps (development tools, deployment tools, performance monitoring, version management, and updating tools). This ensures that the operations team you already have can create, deploy, and manage models at scale, even if they don’t have software development experience or a similarly skilled team backing them up. Such an application will have less functionality than a full MLOps stack can provide, but for most organizations this is the level that their business can support, and, therefore, is the right level to aim for.
Such tools are usually developed with non-data science, non-software engineers in mind. The tasks required to build, deploy, and maintain models are hidden from the end-users. Instead, users only need to respond to periodic queries for contextual information, and the rest of the MLOps tasks are handled in the background.
