

Before explaining fog computing, we need to make sure we have a solid understanding of cloud computing, a concept that has become a common term in our lexicon.
Cloud computing refers to access to “on-demand” computing resources, computing power, and data storage without the need for on-premise hardware or any active management by the user. Figure 1 below shows a very generic architecture representation of how multi-site companies deploy an industrial cloud solution.
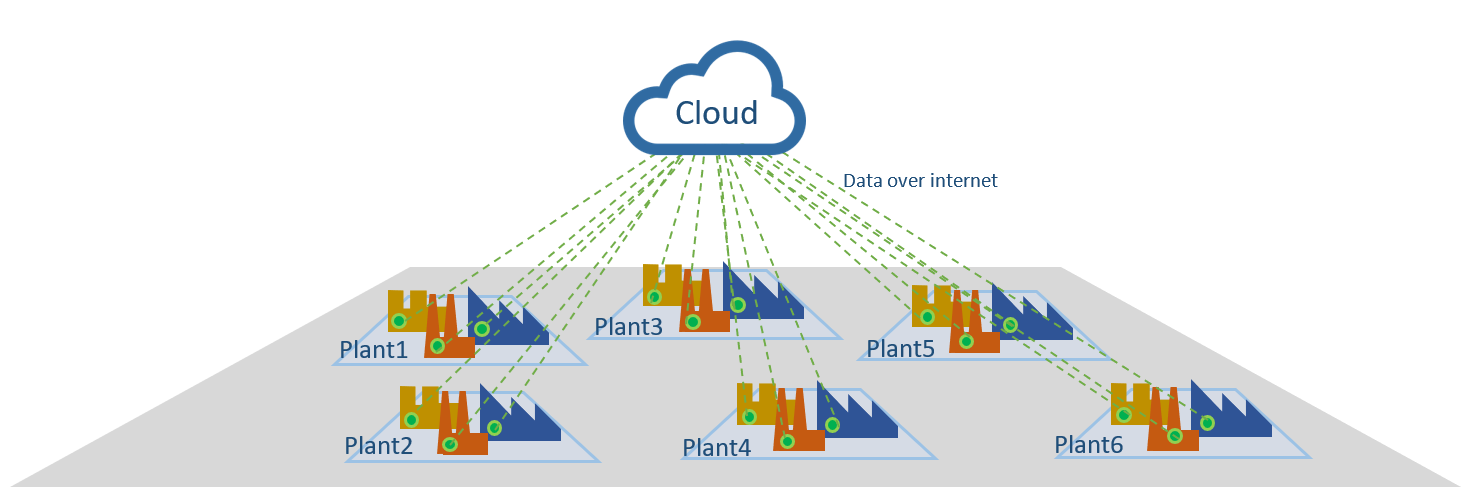 Figure 1: cloud computing architecture. Courtesy of the author.
Figure 1: cloud computing architecture. Courtesy of the author.
Within a cloud architecture, several different adoption models have become very popular—those most notable being infrastructure-as-a-service (IaaS), platform-as-a-service (PaaS), and software-as-a-service (SaaS). The way you want to leverage the cloud for your organization will help guide you as to which model will be the best fit.
IEEE 1934 defines fog computing as “a system-level horizontal architecture that distributes resources and services of computing, storage, control and networking anywhere along the cloud-to-things continuum. It supports industry verticals and application domains, enables services and applications to be distributed closer to the data-producing sources, and extends from the things, over the network edges, through the cloud and across multiple protocol layers.”
In short, this means fog computing focuses on shifting certain cloud computing resources away from the cloud and closer to the individual devices. With fog computing, an additional computer is placed at each plant, typically at the LAN level, to concentrate (or aggregate) data locally. It regulates which information should be processed locally and which can be offloaded to the cloud, acting as a mediator between local devices and remote servers. This generally helps with two things:
- Reduction in the number of cloud connections necessary
- Faster local processing—as shown in Figure 2, the fog computer sends out consolidated and meaningful data to the cloud, where each plant’s information is analyzed in combination with other plants
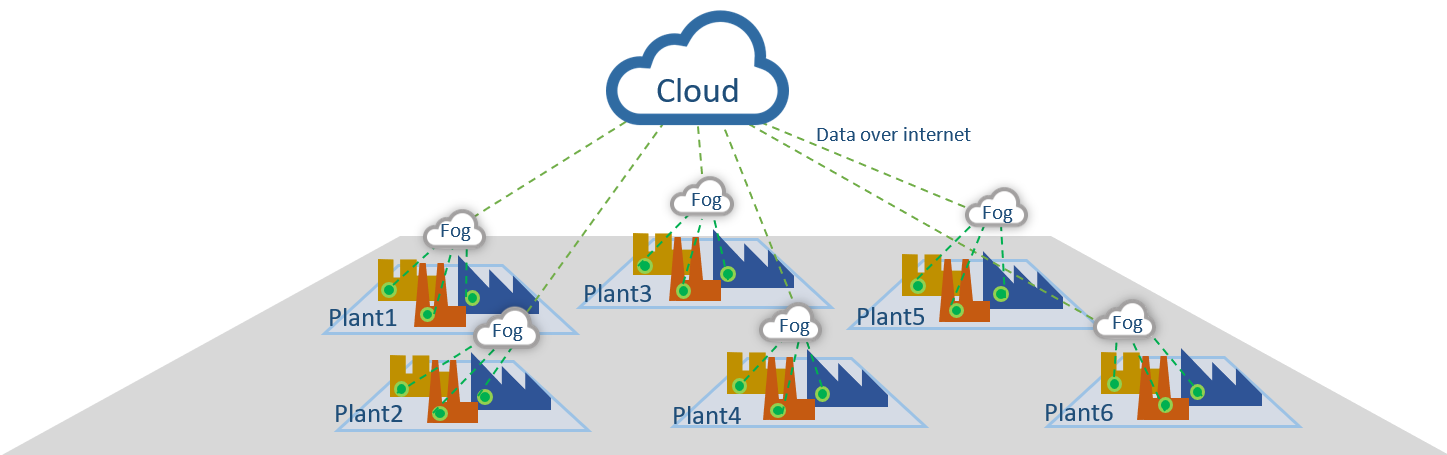 Figure 2: fog computing architecture. Courtesy of the author.
Figure 2: fog computing architecture. Courtesy of the author.
What Are the Differences Between Fog Computing and Edge Computing?
In addition to fog computing, you may have heard another term being used: edge computing. Are they the same? If not, what is the difference?
Depending on who you ask, or what company you work with, the answer may be widely different. Some argue that fog and edge computing are the same thing, whereas others argue they are quite different.
Fog and edge computing, at least in industrial and manufacturing applications, are systems that attempt to collect and process data from local assets/devices more efficiently than traditional cloud architectures. The key difference between these ideas resides in where processing and “intelligence” ultimately takes place.
For example, if a sensor can store its once-per-minute raw measured values locally for a period of 30 days, it may only transmit summary data to a computing resource (server) on the local network once an hour, and a fraction of that sensor data might be forwarded onto cloud computers for processing. This greatly reduced data transmission, and allows a detailed history to be gathered, if something of interest is captured by the sensor.
Your definition of edge versus fog depends on where you draw the boundary around the raw data collection, the data storage, and the use of computational resources.
Benefits of Fog Computing
Consider the example above. Have you imagined the amount of computation power required to aggregate, analyze, and calculate the desired output of 100 sensors? How about 10,000 sensors? The required storage, data traffic, and network bandwidth grows exponentially the more data sources are added.
Fog computing helps you:
- Reduce network latency and data traffic
- Increase the effective network bandwidth
- Vertically isolate the network
- Scale up the deployment easily and efficiently
- Control privacy and data security
By adapting fog computing technologies, you can build and deploy “smart” and efficient IIoT solutions in smaller steps. However, instead of thinking about “cloud vs. fog vs. edge,” you should reframe your thinking around the question, “Which combination is best suited for my particular needs?” This way, it is not viewed as a “one or the other” decision, and rather as a collaborative adaptation of different technologies and architectures.
This article is a product of the International Society of Automation (ISA) Smart Manufacturing & IIoT Division. If you are an ISA member who is interested in joining this division, please log in to your account and visit this page.

