

Overview
In today’s digital economy, every business wants to be data driven. It is one of the top strategic goals of nearly every organization. Designing, building, and enhancing data-driven systems improves the value of enterprise data which can further enhance the business performance. In essence, having the right Data Architecture in place is crucial.
Over time, Data Fabric has grown to be the architecture of choice for many enterprises. But many organizations now feel what they need is a decentralized data architecture. The proactive organizations have already taken a plunge to decentralize the data processing and delegation that lets distributed teams access data effortlessly from a heterogeneous data environment.

So, What is It?
When I came to know this work "Data Mesh" I thought it is some technology like AI/ML or GenAI kind of stuff. After researching and learning a bit about this terminology I understood more about it. So—what it is?
Data Mesh is not a technology or a product but is an organizational and architectural structure that requires teams and culture to be at its center.
In Data Mesh, each functional business unit is responsible for the QA of its data lake and is the owner of its data products. They take the responsibility of data quality and produce ready-to-consume data products for the other BU units to access.
Producing discoverable, addressable, interoperable, and secure data sets are the primary objective of Data Mesh architecture.
Why Data Mesh?
Before we discuss "Data Mesh" at length, we should understand what the problems with current data strategy are followed across the factories.
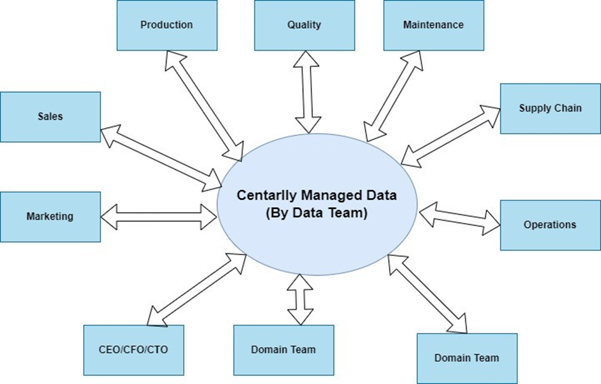
(Centrally Managed Data Platform Diagram)
In the diagram above, we see most of the data—be it from production floor, quality team, maintenance team, sales or any other team in an organization are mostly managed by a central data team in modern factories. The data team typically consists of data scientists, AI/ML engineers, data architects, data platform engineers and platform administrators.
From various data sources (SCADA, Historians, Machines, ERP, MES etc.) of the production plant, the data is being ingested to a centrally managed platform either on-premises or typically on cloud data lake platforms. The data is ingested, transformed, and stored into various data stores like SQL or NoSQL data stores for further consumption.
The above approach is good for some obvious reasons, including:
- Standardization and consistency: (Enforcing consistent data governance, security, and quality policies by centralizing data management)
- Centrally Managed data platform: (A unified data platform that simplifies data integration, storage, processing, and access across organizations)
- Simplified data infrastructure: (Abstracting the complexities of integrating different data sources and technologies)
There are also some challenges in a centrally managed data platform, as listed below.
The first problem:
Self-Serving of data - Self-serving of data is intended as self-service analytics or self-service business intelligence (BI), it is an approach to data analytics that enables end users to access and work with data even if they do not have a background in statistical analysis, business intelligence, or data mining.
The business users are left to query and analyze the data buy their own.
But despite the latest tool sets, No-Code/Low-Code platforms and analytics tools for querying and analyzing data in most cased the business users end of with data silos and the work is siloed.
Why is that so?
Working with the production plants and from my experience what I observed is the main reason contributing to this is the lack of data literacy and lack of understanding about the underlying datasets.
As the underlying datasets are not very clearly defined (like a data contract or data specification), most of the time it is difficult for the business users to make sense of the data. Due to this reason, they query and retrieve the data and make separate sets of the data for their use. It creates a data silo again and there is a duplication of data (Not a single source from the central data platform), users tend to store the data needed by them after querying from central platform to their platform (like local files, local databases etc.)
Let's talk about the solution. In a centralized data platform team most of the time the problem is the lack of domain experts who understands the data domain. For example, if we talk to the quality team or the production team about the data generated by their systems and applications, they can elaborate it with better clarity and reasons behind a data pattern but in a centrally managed data team the domain expertise is less or sometimes nil. This makes the data quality and usability issues.
With "Data Mesh" strategy the data is managed (maintained, curated, extracted, analyzed) by the domain experts who understand the data well. With domain expertise when the analytics is included the produced data will have more business intelligence and more accurate, It can be used by the business users directly without the need of further analytics and manipulation.
The main benefit is to empower the team that really knows the data generated by the various systems of the domain.
The outcome of the data can be treated like a product, which can be used, served, and accessed with a uniform domain standard by the end users directly.
This concept is calling as a "Data Product", data as a product which is verified, trustworthy and the end users know whom to ask if there is any clarification required about the data as there is clear definition of ownership.
The Second Problem:
Most of the time users struggle to find the data they need- A centrally managed data platform has its advantage, but it also comes with scalability issues.
It is very difficult to scale a centralized data platform with ease.
Most cases the team in a central data platform are not aware of the available data and they need support to analyze and extract the required data in a required format from the domain team or the users who need the data. Also, when there are many domains, and each domain may ingest different type of data and their analytics need are also different.
So, what is the solution how "Data Mesh" can support this and help in scaling the platform?
Let's discuss the solution: "Data Mesh" approach suggests that we need to decentralize the data platform and the team.
Instead of a centralized team and platform to manage all the data ingested by various domains and systems, let's have the data platform and the data itself managed by each domain team separately. In this case the data producers as well as the data consumers (analytics users) both are from the same domain, and they understand the data better and what analysis has to be performed and how and where to extract the data is very well known to them.
In this way the domain team can quickly discover the data, they can define which data has potential business impact and how other domain users can use those data.
That means each domain team will have their own data engineers, AI/ML engineers of their own to manage the data. It has also some other impact that we will discuss going further in the topic.
The Third Problem:
Usability of data (interoperability) and the Quality of data is a challenge. When the data is managed by a central team due to lack of domain knowledge as well as the lack of communication between the business users and the data team creates a gap in the quality of data that is being extracted and served to the users.
Most cases the data provided may not fit the need of the users or the analytics application's requirement and the data may not be in a standardized format which can be used/consumed by a specific domain team.
To make the data usable and with quality the domain team must further work on it or must work closely with the central data team to further enhance it, which is very lengthy and cumbersome process and needs extra effort.
So how "Data Mesh" approach can solve this?
"Data Mesh" approach advocates that the data should be treated as a product.
That means we should consider data more than information, the data should be in a well-represented format, should be understandable and should provide us with more business value.
So how it can be done? Like any other product where there is a specification given or derived by the product manufacturer (exp. Type, operating range, product dimension etc.) here also the data must provide with a clearly defined specification or "Contract".
This is called a "Data Contract", where the provider of the data (domain team) defines the type of data, its usage, period of data and other required details in the format the business users need. The data contract provides a well-defined schema with a standard format and adhering to compliance and security standards.
In this way the data is more reliable, trustworthy, quality and the usability of the data is achieved.
For more details on data contracts: Data Contract.
In the above discussion, I highlighted some of the major problems in a centralized data platform and how a "Data Mesh" approach can solve this. However, more problems exist. I'll leave it up to you to analyze.
Now the question— is this approach fit for the modern smart factories? Do the factories must implement it or change their approach for their data management platform?
Let's discuss - The above issues discussed do not mean that "Data Mesh" is the only solution to go with. There are enterprises which are managing their data centrally the requirements of the business users are still fulfilled. But as we discussed above, they may run into those issues sooner or later or already are facing and somehow managing it internally.
"Data Mesh" approach implementation is not going to bring in a major technology change for the organizations. Most of the tech stack and team are already available within the organizations. They just need to be organized as per the business and analytics need.
Implementing a "Data Mesh" requires a cultural shift rather than a more technological shift. It needs a change in the approach how the data is being managed traditionally. Domain experts with additional analytics skill which can be built internally (we don't have to bring experts from outside) are what is required.
Existing people can be trained, and the data team can be restructured to fit the need of each domain.
For large enterprises with many domains and data needs the "Data Mesh" architecture makes perfect sense as per me. As the large enterprises have different analytics, business intelligence needs, and they can manage different data teams for each domain.
But when we compare to small scale industries it may not make sense if the analytics needs and the produced data volumes are smaller in sizes which can be managed by a central team. Also, it is a bit challenging for them to manage separate data teams for each domain due to high operational cost.
Large organizations with current setup of "Central Managed Data Platforms" should analyze the current challenges and the benefits of moving to a "Data Mesh" architecture. It may need some initial maturity assessment for them to find out if they are ready to make a cultural shift of managing their data.
It can be started with small steps like taking a pilot project or POC for a domain which may not be critical and can survive a technology and cultural shift.
The Architecture:
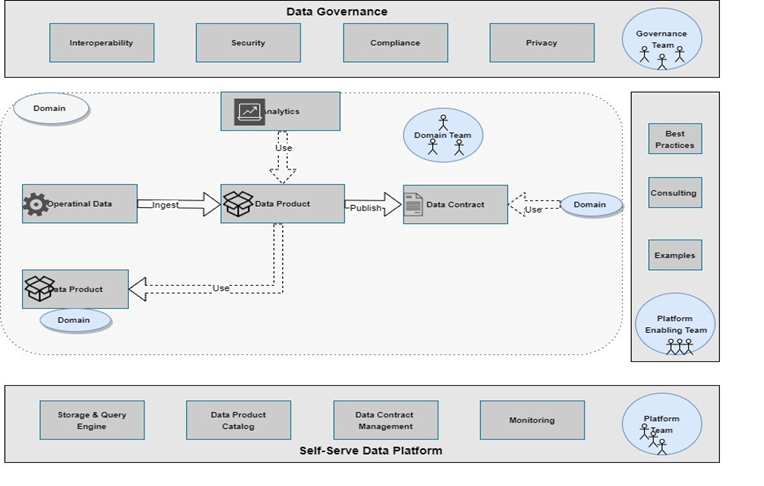
(Data Mesh Architecture Diagram)
The above diagram shows a typical architecture block and the components of "Data Mesh" architecture. It was beyond the scope of this article to go in depth of technical details of it. If you are interested, please have a look at this link "Data Mesh"
Conclusion
For me, it makes sense for me to shift to a "Data Mesh" approach for the "Modern Smart Factory" to properly benefit from it, as it will bring more business capability and use cases. With better data quality and usability the business users can quickly and easily get the business intelligence data for a quicker decision and operation.
More accurate data means the factories can make more analytical decisions and for a modern smart factory and the Industry 4.0 transformation requires more AI/ML based applications, systems, and automated production systems, which can be achieved by "Data Mesh" approach.
I hope you find this article useful! Please comment your thoughts and ideas, suggestions in the comments.
