

This post was authored by Donald G. Dunn, CAP, is a business consultant and former director of engineering of the Phillips 66 Amarillo Division, and Nicholas P. Sands, CAP, P.E., is an ISA fellow, the ISA vice president of standards and practices, and co-author of the ISA book, A Guide to the Automation Body of Knowledge.
If you work in a plant that processes oil, chemicals, pharmaceuticals, power, water, wastewater, or food, you probably have problems with alarms on the automation system. In fact, you probably have the same problems that most other users have. The bad news is that it turns out that the common problems of alarm management are very common indeed, and they contribute to safety incidents, off-quality production, and plant shutdowns.
The good news is that there are common solutions to the common problems. The solutions take significant effort, but they work. There are many plants across all those industries that manage their alarm systems to minimize the common problems and the negative impacts. In those plants, the alarm system is a powerful aid to the operator, indicating the right time to take the right action to prevent an undesired consequence.
Let’s examine seven of these problems, their impact, and their solutions.
1) Too many alarms
The most common problem with the alarm system is too many alarms. Too many alarms can overwhelm the operator. This can lead to undesired consequences if the alarms are real indications of abnormal conditions requiring a response. If the alarms are not, then they will desensitize the operator to alarms and cause an undesired consequence when a real alarm occurs. This is not hype. It really happens. The best measurement for this problem is the average alarm rate, or the number of alarms annunciated per operator console per unit time, averaged over the reporting period. A frequently used form is the average alarms per hour per operator over a month period. The metric is per operator or operator console, because the human limitations of the operator, at a sustained level over a shift, are the basis for the range of accepted values. Operator console is a term for a control room operator’s span of control or area of responsibility.
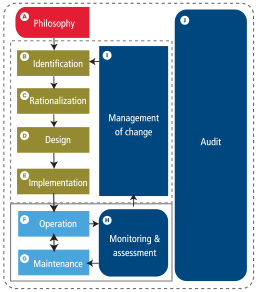 Figure 1: Alarm management life cycle
Figure 1: Alarm management life cycle
Fewer than six alarms per hour is very likely to be acceptable, whereas more than 12 alarms per hour is about the maximum manageable, and more than 30 alarms per hour is very likely to be too demanding. Not everyone agrees with these numbers, and the type of processes and complexity of operator response can affect them as well. Average alarm rates of more than 1000 alarms per hour have been reported, and everyone can agree that is not acceptable.
There are other metrics to provide alternate views of the problem of too many alarms, like the number of standing alarms and the percent time in flood. There are many potential causes to the problem of too many alarms. Possible causes include chattering alarms (see #2) and alarms that do not require a response (see #3).
The key is to measure the average alarm rate to know when it indicates a problem. Please do not add an alarm for high average alarm rate, though. This is a performance metric and is more useful over a period of time than as an instantaneous snapshot.
The ANSI/ISA-18.2-2009, Management of Alarm Systems for the Process Industries, standard requires monitoring the alarm system so that an assessment can be made if the system is performing well or poorly. Of course how the process performs plays a big role in the alarm system performance. Ideally the alarm system only indicates abnormal conditions in the process so that the operator can respond. A system with too many alarms may not be a reliable aid for the operator to prevent undesired consequences.
2) Chattering alarms
One of the biggest contributors to problem number one is chattering alarms. Chattering alarms really desensitize the operator and are the quintessential nuisance alarms. If you have ever seen an operator acknowledge an alarm with his or her back to the console, it was likely a chattering alarm. The measurement for this problem is the number of times an alarm is annunciated twice to the operator less than a time interval apart (often 60 seconds is used). The alarm goes through a repeating cycle of alarm – return to normal – alarm. A cluster is the group of alarms before the chatter cycle is broken, and the cluster size is the number of alarms in a cluster.
Chattering alarm counts of more than 100,000 per day have been reported, which at some point become essentially one cluster. Assuming for the sake of argument that the alarm is needed (see #3) and the alarm set point is correct, chattering alarms are often caused by alarm design issues, though instrument maintenance is also a frequent cause. Part of alarm design is the selection of the alarm attributes to prevent chattering: deadband, on-delay, off-delay. On-delay delays the alarm annunciation, where deadband and off-delay delay the alarm return to normal. This selection is sometimes included in alarm rationalization. Applying an alarm deadband of 1 percent or off-delay of 5 seconds dramatically reduces chattering. Adding an off-delay of 60 seconds converts a full cluster of chattering alarms to a single alarm.
As part of the continuing evolution of ISA-18.2, a series of ISA18 technical reports (TRs) is being developed to help alarm management practitioners put the requirements and recommendations of ISA-18.2 into practice. If you are interested in contributing your knowledge and experience to the TR development effort—and in gaining from the knowledge and experience of your professional colleagues at the same time — contact ISA18 co-chairs Nicholas Sands or Donald Dunn.
3) Alarms that do not require a response
It seems to be a common problem that alarms are used to make operators “aware” of conditions. This misconception is based on the assumption that the alarm function is the only method of communication between the automation system and the operator. The result is further desensitization of the operator to alarms. Using alarms for awareness, though a common practice, violates the definition of alarm. An alarm is an audible and/or visible means of indicating to the operator an equipment malfunction, process deviation, or abnormal condition requiring a response. This is a difficult problem to measure.
The best measure, after completing the time-consuming activity of rationalization, is the number of alarms that did not require a response and were removed. It is not uncommon to remove 50 percent of alarms during rationalization. This is not to say the objective of rationalization is to remove alarms. The objective is to make sure you have the right alarms, at the right set point, with the right priority, and with the right documentation to train the operators.
Rationalization may designate some indications, not as alarms, but as alerts. Alerts are indicated on a different list from alarms, separating the “important” from the “urgent and important.” Alert is defined as audible and/or visible means of indicating to the operator an equipment or process condition that requires awareness and which does not meet the criteria for an alarm. Another common cause for this problem is alarms that stay in alarm for extended periods (see #4).
4) Alarms that stay in alarm
The alarm summary may be filled with stale alarms, or alarms that remain in alarm more than 24 hours. These may be alarms that do not require a response (see #3) or alarms that once did require a response, but the response is no longer needed. These alarms clutter the alarm summary and desensitize the operator. Although some people may disagree, stale alarms are by definition considered nuisance alarms. The measurement of stale alarms is easy: the number of alarms annunciated (on the alarm summary) over 24 hours. Stale alarms as old as 13 years in alarm have been reported. Certainly that alarm was not needed. 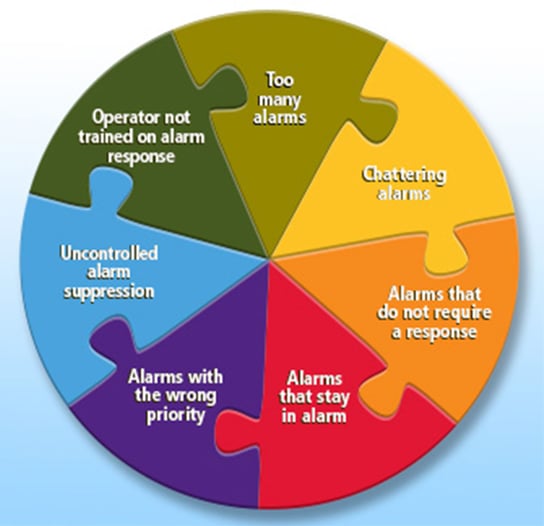
Two common causes for stale alarms are control system configuration practices and lax management of change. One survey of stale alarms found approximately 30 percent were on equipment that was not operating because it was not needed at the time. For example, the basic configuration practices created an alarm that a pump was not running—even when the pump was intentionally not running.
Good basic configuration practices prevent many alarms. A second cause for stale alarms is poor management of change. When equipment is removed from the field, the alarms should be removed from the control system, or at least decommissioned, as part of the management of change process. It is not uncommon to find alarms at the bottom of the alarm summary for equipment that was removed years ago.
5) Alarms with the wrong priority
Many alarms have the wrong priority assigned, which makes priority less meaningful for the operator, and potentially meaningless. This can lead to the wrong choice of action when multiple alarms occur. It is worth noting that for batch processes (ISA-TR18.2.6-2012), alarm priority often needs to change from process step to step, so that if a single priority is specified for an alarm during rationalization, it is likely that the priority will be OK for some process steps but not others. Measuring this problem also occurs only after rationalization.
A consistent method of prioritization based on consequence severity and time to respond can radically change the alarm priorities. In some cases, 80 percent of the alarm priorities have been changed, mostly to a lower priority. Priority should be based on how urgent it is for the operator to take action. This is often not the case. And at many sites, no consistent system was used to assign priority. It was often left to the discretion of the process or control engineer. There was a pervasive approach to priority, actually hard coded in some control systems, that the further the process variable was from the normal range, the higher the priority assigned to the alarm.
This is based on the wrong consequences. Alarm priority should be based on the operator-preventable consequence, the difference in consequence between scenarios where the operator does and does not respond. A common mistake is to evaluate the operator-preventable consequence using the same methods as a process hazards analysis (PHA). There are three significant differences between evaluating the consequences in rationalization versus PHA:
- Mitigated versus unmitigated: The PHA looks for the consequence with no safeguards or layers of protection. In rationalization, all the layers of protection work, or there are specific alarms to identify the failures. For example, in rationalization the safety interlocks are assumed to work. Otherwise the consequences for which the safety interlock was specifically designed are assigned as the operator-preventable consequence.
- Proximate versus ultimate: The PHA looks for the ultimate consequence from a chain of events. In rationalization, the consequence of inaction leads only to the next step in the chain of events, and not the ultimate consequence. For example, a high-level alarm may provide a chance for the operator to respond to prevent a trip of the high-level interlock. The consequence of inaction is that the interlock will trip, and not that the tank will overflow because the interlock fails.
- Probable versus possible: The PHA rightly looks for unlikely events that may cause catastrophic consequences, once every thousand years or more. Rationalization should focus on the probable causes and probable consequences. The list should be short and clear to train the operator on what actually happens in a plant every day. Troubleshooting should not start with the least likely cause for a problem, but the most likely.
It makes an amazing difference when the alarm priority is consistent and based on the urgency of the operator action.
6) Uncontrolled alarm suppression
Often uncontrolled alarm suppression is discovered when the undesired consequence occurs, because there was no alarm to spur the operator to action. There are better ways to find this problem. The measurement for uncontrolled alarm suppression has two parts: measurement of supposedly controlled shelving of alarms, and measurement of alarms taken out of service without authorization. There are three types of shelving defined by ISA-18.2, which, to paraphrase, are:
- Designed suppression: The engineering controls of designed logic control the suppression and unsuppression of alarms.
- Shelving: An operator suppresses alarms, and engineering controls in the shelving system control the unsuppression of alarms.
- Out-of-service: The administrative controls are used to control the suppression and unsuppression of alarms.
Both shelving and out-of-service can be misused. Shelving should not be used without a monitoring system that reports the most shelved alarms, which should be reviewed for potential changes. Out-of-service alarms can be suppressed for years without resolving the issues, which are typically instrument related. This form of suppression should also be monitored and reviewed to prevent abuse.
7) Operator not trained on alarm response
Another problem that is difficult to measure is the number of alarms for which the operator, any operator who is supposed to respond to the alarm, does not know the action to take in response. This leads to the undesired consequence the alarm was designed to prevent, because the correct action was not taken. Alarms exist only to prompt the operator to take corrective action. If there was no operator, there would be no alarms.
For the alarm function to work, the operator has to take the corrective action. That action must be known or quickly available to reference. Alarms implemented without rationalization or operator training often cause this problem. Measuring the problem is possible by reviewing the operator training program, and it is not surprising that improving the training program is the solution. The rationalization process captures the key information for operator training, including:
- the probable cause of the alarm
- the corrective action to take in response to the alarm
- the consequence that occurs if no action is taken
This information is sometimes called the alarm response procedure.
Alarm management
This is not an exhaustive list of the problems with alarm systems, but these seven are some of the most common. Breaking down each problem shows how it can be measured and solved. It is no accident that the solutions are all activities in the ISA-18.2 alarm management life cycle. Rationalization, design, monitoring and assessment, operation, which includes training and control of suppression, and management of change are some of the key activities of alarm management. Through these activities, and the rest of the life cycle, the common problems of alarm systems can be minimized, and the alarm system can be the aid to the operator we all wish it was.
About the Author
Donald G. Dunn, CAP is a business consultant and former director of engineering of the Phillips 66 Amarillo Division. He has more than 25 years of industry experience, and was past ISA vice president of standards and practices. Dunn has a B.S. in electrical engineering from Prairie View A&M. He is currently a senior member of the IEEE and ISA. In addition, he is the co-chairman of ISA standards committee ISA18, which authored the first industry standard on alarm management, and is the convener of IEC 62682 – Management of Alarm Systems for the Process Industries.
Connect with Donald![]()
About the Author
Nicholas P. Sands, P.E., CAP, serves as senior manufacturing technology fellow at DuPont, where he applies his expertise in automation and process control for the DuPont Safety and Construction business (Kevlar, Nomex, and Tyvek). During his career at DuPont, Sands has worked on or led the development of several corporate standards and best practices in the areas of automation competency, safety instrumented systems, alarm management, and process safety. Nick is: an ISA Fellow; co-chair of the ISA18 committee on alarm management; a director of the ISA101 committee on human machine interface; a director of the ISA84 committee on safety instrumented systems; and secretary of the IEC (International Electrotechnical Commission) committee that published the alarm management standard IEC62682. He is a former ISA Vice President of Standards and Practices and former ISA Vice President of Professional Development, and was a significant contributor to the development of ISA’s Certified Automation Professional program. Nick is the co-author of the ISA book A Guide to the Automation Body of Knowledge, and has written more than 40 articles and papers on alarm management, safety instrumented systems, and professional development. Nick is a licensed engineer in the state of Delaware. He earned a bachelor of science degree in chemical engineering at Virginia Tech.
Connect with Nick![]()
![]()
A version of this article also was published at InTech magazine.
