

In May 2011, the management consulting firm McKinsey & Company released a research report titled Big data: The next frontier for innovation, competition, and productivity. This was a seminal report, but it certainly did not cause the big data explosion. The concept of big data is as old as computing and has long been used to describe data volumes exceeding the cost or capability of existing systems.
After 2004, the term “big data” began taking on its more modern meaning after Google released two papers on computing models for dealing with large data sets. It just happened that the McKinsey report was well timed to the explosion of awareness and interest in big data. After staying flat for many years, the number of Google searches for “big data” tripled in the 12 months after the report was released, and after 36 months increased by 10 times.
In a more recent McKinsey report, the figure 1 chart drills into data sources by industry. Manufacturing is far and away the leader, with 1,812 petabytes of data produced: 1,072 from discrete manufacturing and 740 from process manufacturing. These numbers have grown exponentially over the past five years or so, as the costs of creating, collecting, and storing data have decreased exponentially.
Note that the figure 1 data is presented in petabytes, a volume of data that was considered almost science fiction just a decade ago. Wired magazine wrote an article in 2006 surveying the explosion in data volumes and the innovative techniques available to gain insights from this data, declaring the arrival of the “Petabyte Age.” Less than a decade later a petabyte is, if not trivial, at least an unremarkable volume of data to store and process, with terabytes relegated to memory sticks handed out as trade show trinkets. But enough about the origins of big data, let’s look at how it is affecting manufacturing, specifically on the process side.
Big data in the process industries
Process industries can reap substantial benefits from intelligent big data implementations. As figure 2 illustrates, McKinsey sees a $50 billion opportunity in upstream oil and gas alone, and other process industries can expect similar outcomes.
In addition to having the largest volume of data compared to other sectors of the economy, manufacturing organizations also have the longest history of generating and storing large volumes of data. The digitization efforts of plants implementing programmable logic controllers, distributed control systems, and supervisory control and data acquisition systems in the 1970s and '80s gave the industry a head start over later data generators.
This is why some vendors refer to manufacturing sensor data as "the original big data," or claim they have been supporting big data for years. These claims obscure some important facts about big data. It is not just about data volume, although it is certain that data volume in manufacturing will continue to grow. Pervasive sensor networks, low-cost wireless connectivity, and an insatiable demand for improved performance metrics will all continue to drive increased data volumes as the big data's partner in hype, the Industrial Internet of Things (IIoT), continues its momentum.
Despite the long history and large volumes of data associated with process manufacturing, the reality is that manufacturing organizations are considered laggards in exploiting big data technologies. Big data solutions in other industries are easy enough to find: credit card companies with fraud-detection algorithms, phone companies with customer churn analytics, and websites with product recommendation engines.
In our lives as consumers, we interact with the implications of these big data solutions every day in experiences as simple as using Google. Yet in manufacturing plants, the experience with big data is a mixed result of slow adoption, limited accessibility, and confusion.
Here are some of the main reasons that process plants have often been slow to exploit the potential of big data:
- Big data implementations can be expensive and resource intensive, and are therefore frequently an initiative led by information technology (IT), and the typical implementations of big data in manufacturing organizations follow this model. Typically, these solutions do not fit the needs of front-line engineers or analysts within manufacturing plants. So, for ad hoc investigations of asset, yield, and optimization-these heavyweight big data systems are a mismatch to front-line requirements.
- In industries where expected plant and automation system lifetimes are measured in decades, new technologies that require substantial modifications to existing systems will not easily or quickly be introduced into brownfield operations. Instead, new technologies must be engineered to fit existing plants and context, which means vendors need to create bridges from innovative technologies to existing infrastructures. Only now are vendors beginning to offer software solutions bringing big data innovations to the employees as an application experience or to the plant floor with modern predictive analytics.
- Confusion often blocks broader acceptance of big data innovations, for example, the assumption that "big data equals cloud." The public cloud-an Amazon, Microsoft Azure, or SAP HANA platform-may offer the best price or performance model for data collection, storage, and processing, but there is nothing about big data that requires a cloud-based model. Other misunderstandings include, "I'm already doing big data, because I use statistical process control, advanced process control, principal component analysis [PCA], or some other analytics evaluation" or the assumption that big data is neither new nor relevant to the needs of process manufacturing plants, harkening back to the "we've been doing big data forever" claim noted earlier.
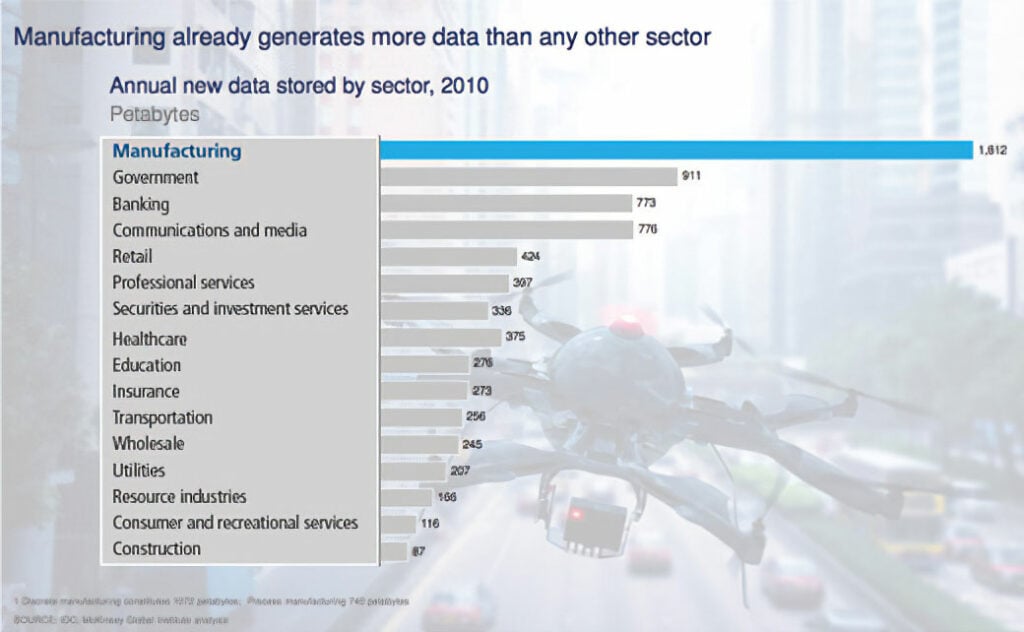 Figure 1. When it comes to generating big data, no sector of the economy can match manufacturing.
Figure 1. When it comes to generating big data, no sector of the economy can match manufacturing. Source: McKinsey
Framing the issues
To overcome the confusion and blocking issues associated with big data in manufacturing, a new approach is needed, as outlined below. First, it is helpful to frame the ways that "big data" is used as both an umbrella term for the big data phenomena, and in three distinct contexts.
- Big data is the expansion in data volume spurred by ongoing reductions in the cost of data creation, collection, and storage. When data was expensive, less was collected. As generating and storing data has gotten cheaper, the quantity of data has grown. The numbers are staggering, with more data stored in just minutes now than during multiple-year periods in the 1960s.
- Big data is the application of technologies, particularly the innovation in solutions to manage, store, and analyze data. This includes new hardware architectures like horizontal scaling, new computing models like the cloud, new algorithms like MapReduce (the core of the Hadoop ecosystem), new specialists like data scientists, and new software platforms like the 100-plus NoSQL database offerings. A brief reading of any technical publication will quickly show options and offerings greatly exceeding the grasp of all but the most committed observer.
- Finally, big data is the promise, namely the expectation, of business executives that value will be created by combining the volume and technologies of big data to produce insights that improve business outcomes. This could also be the pressure of big data, the demand that business leaders "check the box" and show the organization is tapping big data to achieve better results. These expectations and market pressures cause many companies to store vast amounts of data without a clear idea of how to derive value from it, which often leaves them data rich but information poor (figure 3).
With these three points as a framework, we turn next to the question of what is really different today from the past. If process manufacturing firms have been storing vast amounts of data, what is new now or will be different in the future?
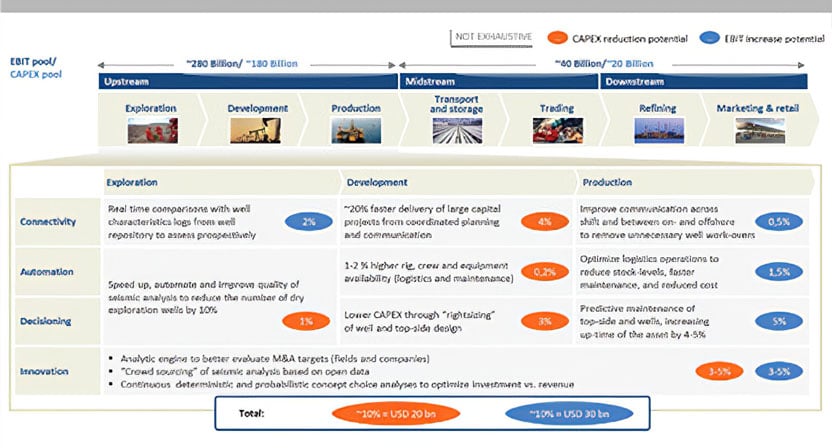 Figure 2. Process industries have much to gain from intelligent big data implementations,
Figure 2. Process industries have much to gain from intelligent big data implementations, with a $50 billion opportunity in upstream oil and gas alone.
Source: McKinsey
Big data innovations
The first innovation is how growth in data volumes and types will be directly correlated to the lower prices associated with data generation and collection, so new solutions powered by big data will cost less in aggregate than previous generations of solutions. This is not always apparent as the market transitions to this new model, but what is expensive now in either cost (such as data expertise) or in impact (such as data movement and architectures) will become less expensive. A partial list of factors driving price down is:
- the hyper competitive cloud computing market
- open source software
- commodity hardware and storage systems
- the availability of software and expertise to derive insights from new data
- the general proliferation of commercial off-the-shelf hardware and software
The second significant big data innovation is the range and depth of algorithms and approaches available to organizations to find meaning in their data sets. Just as big data is a neighbor to the IIoT phenomena, it is also tied to the advances in machine learning and artificial intelligence. Therefore advances in cognitive computing-a composite term including machine learning, artificial intelligence, and deep learning-will become available to process manufacturers to accelerate and focus their analytics efforts. And the use of algorithms and tools available today-including regression, PCA, and multivariate analysis-will be made easier and more accessible to engineers, accelerating their efforts via software that converts big data analytics into easy-to-use features and experiences.
The third big data innovation is a more flexible model for analytics across data sources. This could be required because the data is consolidated and indexed as a single unit or because disparate data silos need to be connected and accessed more easily. In either case, the desired outcome is the same: unfettered integration and access to disparate data sources and types. "Contextualization" is the typical term for this capability in manufacturing environments; other terms for this flexibility in data types and architectures include data fusion, data harmonization, and data blending.
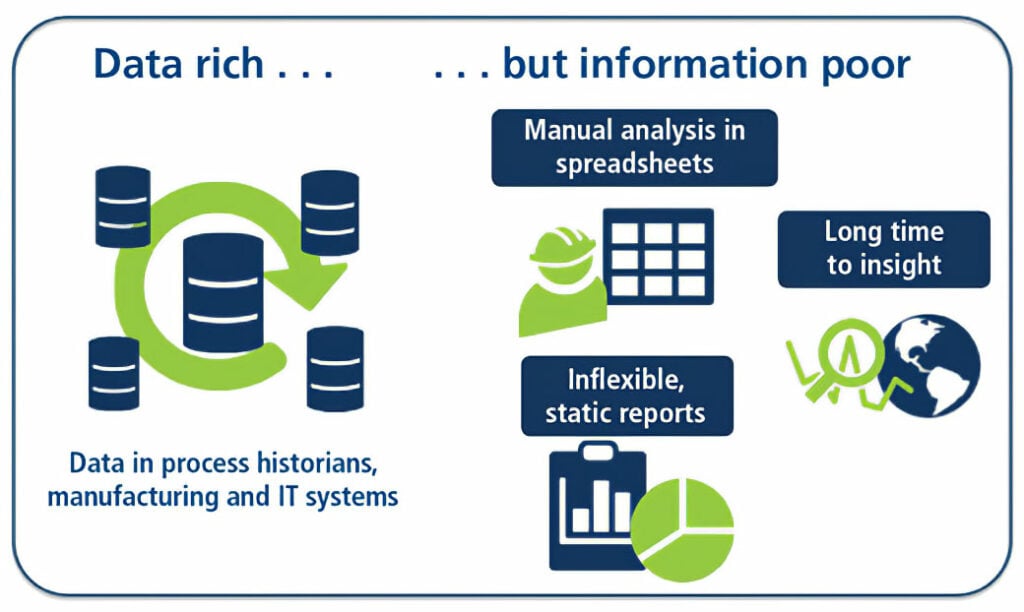 Figure 3. Many process industry firms find themselves awash in
Figure 3. Many process industry firms find themselves awash in data but thirsting for information.
Data lakes
Big data solutions must include a flexible data model to accelerate and enable analytics across any set of data sources. There are as many models for accomplishing this as there are organizations, but the most basic types are a data lake and a distributed model.
A data lake is the modern instance of a data warehouse, except the data is of many types and typically indexed or architected for use by data scientists or developers. Data lakes are usually the domain of centralized IT departments that can afford the infrastructure and expertise-and manage the governance, security, and data models of these corporate-wide solutions.
Not every company needs or can afford this top-down approach, however, so an alternative is simply to enable connections across data silos in situ. This enables engineers to tap any resource on demand. The second approach is more bottom-up and user driven, because there is no data lake required.
Data into information
As ever more data is generated, there are often fewer experts and resources available to inform and interpret the data. The retirement of seasoned engineers and the squeezing of budgets mean the big data equation in many industries is "more data with increased demands for analysis and information with fewer resources." Can the gap between engineers and data be closed, such that executives can start to see real results using the limited personnel resources on hand?
The software innovations required to deliver on this promise are similar to those already in place in numerous commercial software apps and web-based tools:
- accessibility via a browser or app to provide a web-based interface
- useable by process experts and manufacturing engineers
- lightweight deployment not requiring data duplication, along with extract-transform-load operations
- designed for time series data analysis in process plant and other manufacturing applications
- features that apply machine learning and other advanced algorithms to simplify analysis
- interactive, visual representation of data and results (figure 4)
- ability to quickly iterate and to combine one result with another
- ease of collaboration with colleagues within and across companies
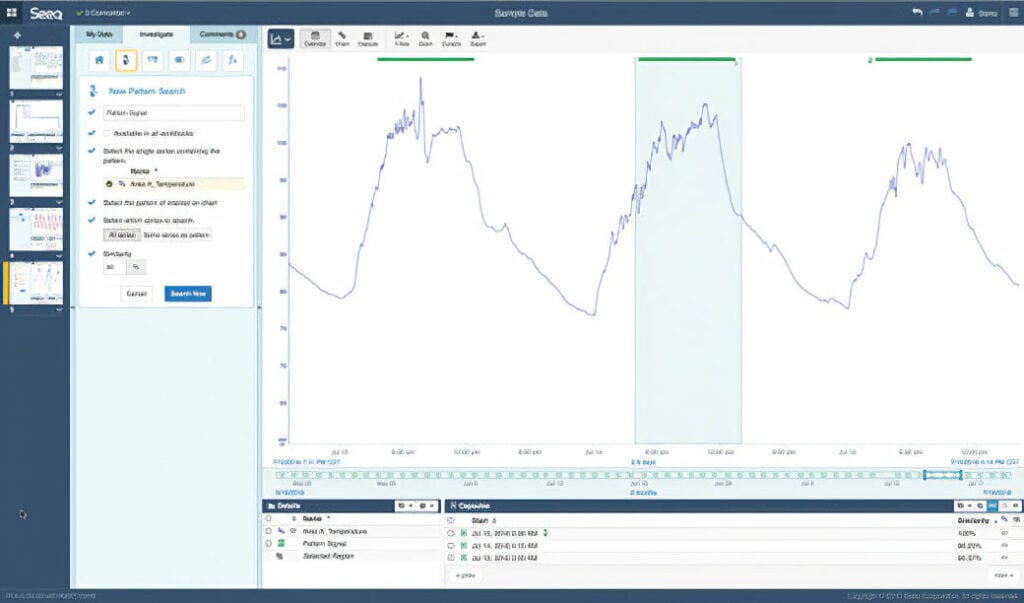 Figure 4. Data analytics provide engineers with visual representations of data to help
Figure 4. Data analytics provide engineers with visual representations of data to help them create actionable information.
Analytics in action
Asset optimization, overall equipment effectiveness, and uptime are not new concepts. There have been generations of preventative maintenance, enterprise asset management, asset performance management, computerized maintenance management, and other systems offered to ensure higher availability of critical resources in production facilities. What is changing with big data is that asset expertise is now available as a service from automation and equipment vendors.
There are examples of this already, but now the cost of data collection, storage, and analytics will make these offerings more accessible. In addition, the new services will have more advanced algorithms and be run across more data to improve the accuracy of the system.
For example, who knows the most about the performance of your turbine: the manufacturer, the local sales rep, or you? The easy answer is the manufacturer. There is a theorem in computer science that what best powers accuracy is greater amounts of data. Instead of relying on an on-site engineer with limited time and capacity to become an expert in an asset class and history, organizations can tap the specific expertise of vendors to manage their most critical assets worldwide.
And for organizations that do have the capacity and resources to develop in-house expertise, their engineers can take advantage of both vendor expertise and local process context to address asset optimization within their manufacturing facilities. Remote monitoring, predictive analytics, and field management systems will therefore become an increasing part of the budget and operational plans for asset-centric organizations, which of course describes many process industry firms.
Big data represents the present and future of data management for all industries. Given the quantity of data and the long history of data centricity, big data has particular relevance to the process industries. Being able to see through the hype and understand how data and analytics can improve outcomes is a critical step for engineers and plant managers alike to realize actionable insights and improve production.
A version of this article also was published at InTech magazine.

