

Closed Loop Automation Use-Cases with Kubernetes Cloud
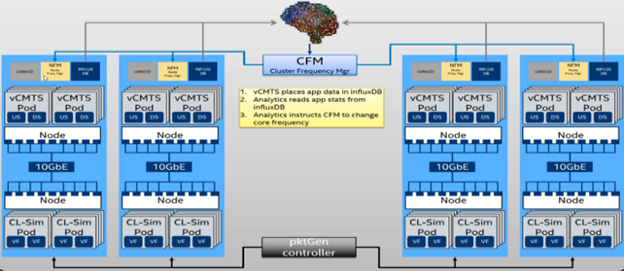
Figure 1: vCMTS Deployment Topology with Kubernetes
Abstract
This article showcases the advancements made through utilizing Anuket Barometer project by introducing local and remote corrective action frameworks with industry standard cloud native orchestrators like Kubernetes, monitoring agents like Collectd, Time Series Database (TSDB) like Prometheus and InfluxDB for widely adopted network function virtualization (NFV) use-cases of Virtual Border Network Gateway (vBNG) and Virtual Cable Modem Termination Systems (vCMTS). Leveraging advanced platform reliability and adaptive power saving telemetry, the demo provides methodologies to identifying the platform capabilities and provision them for optimal run time power savings and reliability.
I. INTRODUCTION
The industry trend to zero-touch Network and Services Management [1] requires operational services to be automated in a similar manner to information technology (IT) and data center infrastructure. Communication service providers often look for improving automation of reliability and power efficiency of their cloud deployments. Many existing methodologies rely on troubleshooting after the fact faults or outages occur.
Energy efficiency plays an important role in reducing operational expenditure and the objective is to automate the power control schemes and achieve the best combination of throughput, packet latency, and packet loss while achieving cost savings. This article shows two use-cases to illustrate closed loop automation, a resiliency use-case, and a power efficiency use-case. The architecture of the use-case demonstrations consists of an open industry standard platform telemetry layer, using Collectd, an open monitoring and alerting infrastructure with Prometheus, and an open orchestration system with Kubernetes to provide the key building blocks for an open closed loop automation architecture which can expand to many communications service provider use-cases.
II. KEY CONCEPTS & DESCRIPTION
This article outlines two use-cases of closed loop automation, a resiliency use-case demonstrated using a Virtual Border Network Gateway (vBNG) and a power efficiency use-case demonstrated using a Virtual Cable Termination Modem System (vCMTS) leveraging Data Plane Development Kit (DPDK) [2].
A. Power Savings with vCMTS
Service providers are looking to reduce the power footprint consumed by virtual network functions (VNFs) and advanced intelligent automation (IA) platform features like Intel Speed Select, helping provide the required platform support to accomplish this. The first part of this demo showcases “intelligent” scaling of central processing unit (CPU) Core Frequencies associated with vCMTS instances running in the Kubernetes environment based upon key performance indicators (KPIs) gathered via Collectd in order to achieve “better” power consumption, as shown in Figure 1. The demo would scale CPU frequencies based on current KPIs. During times when bandwidth requirements are lessened, the CPU core frequencies are scaled down to achieve power savings and vice versa as there is more compute power required for each vCMTS instance. This is done in conjunction with reducing the traffic flowing from the traffic generators; the systems are not expected to be able to perform at the same level with a reduction in core frequency.
B. Closed Loop Resiliency with vBNG
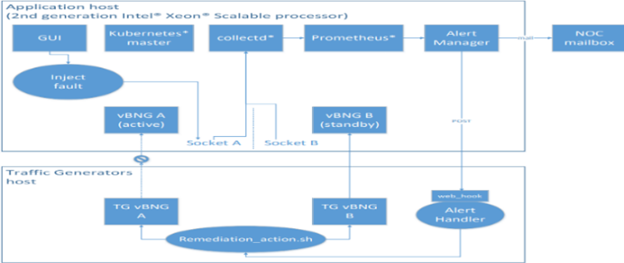 Figure 2: Closed Loop vBNG Demo Topology
Figure 2: Closed Loop vBNG Demo Topology
Broadband Network Gateway (BNG) is the access point for subscribers, through which they connect to the broadband network. One area of significant interest to service providers in recent times is the relationship between automated operations and excellent customer experience [3]. The demo shows that by using x86 platform specific metrics and events, we can monitor the health of the platform and identify issues that may impact the end-user experience of vBNG.
The solution is application agnostic, but we have selected a DPDK-based vBNG reference application to showcase the closed loop fail over and resiliency capability using a platform generated fault, with orchestration changes resulting in the restoration of vBNG service, as indicated in Figure 2. We trigger a platform fault which is reflected via a platform metric and as part of the closed loop error detection and correction. The traffic will be switched from the active to the standby application to maintain an uninterrupted service. We run two vBNG instances at the start of the demonstration, [A] active and [B] standby, on two non-uniform memory access (NUMA) nodes on a single server platform. The vBNG instance created by Kubernetes will start processing traffic immediately when the traffic becomes active.
III. DEMO PROCESS
A. Closed Loop Automated Power Savings Demonstration with vCMTS
The vCMTS solution utilizes DPDK for packet processing; DPDK usually fully utilizes CPU Cores assigned to the poll mode drivers—they run at full speed even when there is not a lot of traffic. The vCMTS demo will show when the workload (bandwidth) requirements lesson over a period of time, intelligent CPU Core Frequency changes significantly to reduce power utilization without sacrificing performance. The demo shows several comparative screens showing power consumption when no scaling is performed; the savings when a cluster centralized agent utilizing machine learning makes frequency changes based upon KPIs gathered from Collectd means we hope to show power savings achieved by a node-local agent with an extremely tight reaction time achieved by locally monitoring specific platform KPIs.
B. Closed Loop Automated Resiliency Demonstration with vBNG
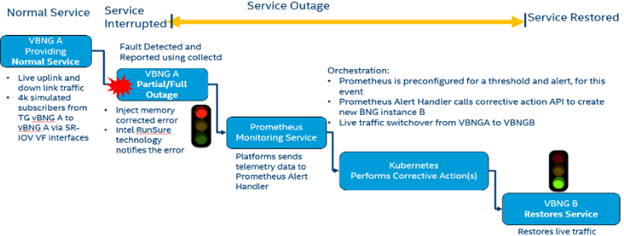 Figure 3: Demo Process Description with vBNG instance
Figure 3: Demo Process Description with vBNG instance
- Stage 1: Server 1 hosts two vBNG instances deployed by Kubernetes. vBNG instance 1 is in active mode receiving traffic on socket 0, the other vBNG instance B is in standby on socket 1 with Collectd running and integrated with Prometheus. Server 2 hosts the traffic generator for the 2 vBNG instances and Prometheus Alert Handler (PAH).
- Stage 2: Error scenario is triggered by injecting 5 correctable memory Reliability Availability Serviceability (RAS) fault, resulting in dual in-line memory module (DIMM) failure on socket 0. Collectd sends these events to PAH. An alarm is raised to alert that a DIMM requires maintenance while triggering the remediation action.
- Stage 3: In this instance, the remediation action is to stop traffic on vBNG instance 1 and start it on vBNG instance 2, resuming the service as normal with minimal disruption to the service for the customer.
IV. HIGHLIGHTS OF INNOVATION
A. Energy Efficiency & Power Savings
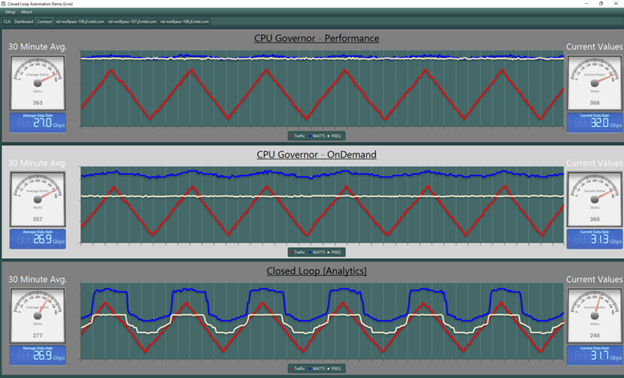 Figure 4: Power Savings of ~80–100 W with Closed Loop Automation
Figure 4: Power Savings of ~80–100 W with Closed Loop Automation
Figure 4 provides a quick visualization of power savings that can be achieved without sacrificing performance.
B. Automated Resiliency & Reliability
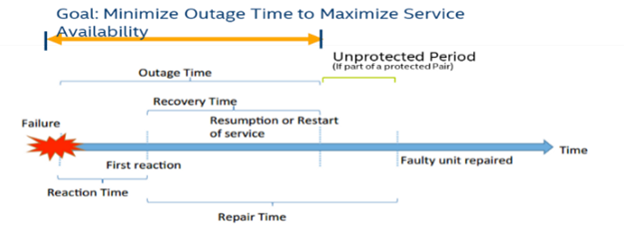 Figure 5: Automated Maximization of Service Availability
Figure 5: Automated Maximization of Service Availability
For resiliency and availability scenarios, the key system metrics are indicated in Figure 5 [4]. The demo provides insights to reduce downtime due to hardware faults, improve resiliency, and apply corrective action in an automated way.
Editor’s Note: This article was originally submitted and published to IEEE/IFIP Traffic Measurement and Analysis’ 2019 conference by authors Sunku Ranganath, John Browne, Patrick Kutch, and Krzysztof Kepka. The demos won the “Best Runner Up” award. All rights reserved. A version of this article originally appeared in Medium.
This article is a product of the International Society of Automation (ISA) Smart Manufacturing & IIoT Division. If you are an ISA member and are interested in joining this division, please email info@isa.org.
References
[1] Industry Sepcification Group Zero Touch Network Service Management, ETSI, etsi.org/technologies/zero-touch-network-service-management.
[2] Linux Foundation Projects, Data Plane Development Kit, dpdk.org.
[3] Broadband Forum Technical Report, TR-345 BNG & NFV, broadbandforum.org/technical/download/TR-345.pdf.
[4] OpenSAF and VMware from the Perspective of High Availability — Ali Nikzad, Ferhat KhendekMaria Toeroe Concordia University Ericsson SVM’2013 — Zurich — October 2013.

