

Approaches and Applications Toward Managing the Network Data at Run Time in a Data-Centric Way
This article provides a detailed view of approaches, methodologies, and applications toward managing the network data at run time in a data-centric way. We present a foray into data-centric architectures with introduction of Lambda architectures by explaining the approach required by domain experts and data scientists alike into data analysis. We then present the fundamental concepts and constructs required to understand Lambda architectures by contrasting data circuits with building electronic circuits. Finally, utilizing a test bed with CLOS architecture, we leverage sFlow, GoFlow, and Apache Kafka to present a model that can analyze and manage network data at run time at-scale.
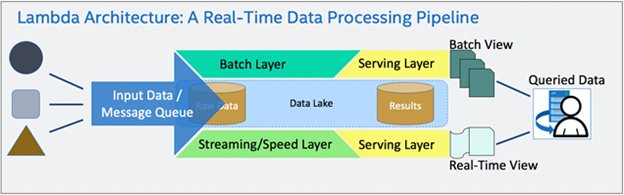
Figure 1: Real-Time Data Processing with a Lambda Architecture [3]
I. Introduction
Data Center Network (DCN) faults are hard to debug due to its complex network and large scale. A large DCN accommodates over 10,000 switches and 100,000 physical servers, each with 10 and 40 Gbps network connections. Aggregate traffic can easily exceed 100 Tbps at peak utilization. Due to the scale of DCNs, debugging faults in a timely manner is a big challenge that administrators often undergo.
To troubleshoot, one must need:
1) Sample packets in flows,
2) To collect and analyze the data in real-time, and
3) Design and test algorithms for potential causes.
We present a unique solution:
1) To identify runtime flows in DCNs, and
2) To detect and create notifications when large flows are present at-scale.
To do proper data analysis in the data center and create intelligent solutions, such as leveraging results from trained machine learning (ML) models to enable dynamic closed-loop processes in a software-defined context, it is important to understand the hierarchical relationship of data and analytics required to adapt such a solution in the first place. Integrating open-source components, we present the following methodologies, approaches, constructs and analysis of run time network data management:
- sFlow
- Packet Sampling
- GoFlow UDP client
- Apache Kafka Streams
- Grafana
II. Data-Centric Architectures
A. Approach to Data Analysis
Similar to Maslow’s hierarchy of needs, a fundamental lesson taught in psychology [1], the “data-centric” hierarchy of needs (Figure 2) essentially translates to the following types of roles associated with each hierarchical layers [2]:
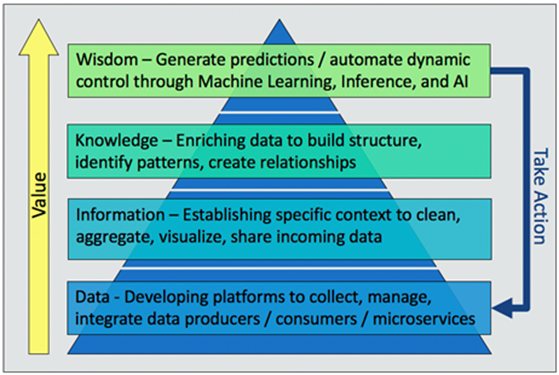 Figure 2: The “Data-Centric Hierarchy of Needs” Value Pyramid
Figure 2: The “Data-Centric Hierarchy of Needs” Value Pyramid
- Data Level: At the most fundamental level of the hierarchy pyramid resides data collection and management software. Traditional software engineering and development-type roles help to deploy the foundational code base and establish best practices for source management in a data collection context.
- Data Level and Information Level: Data operations engineer-type roles reside at the next level of the hierarchy, operating as an interface between the foundational data collection level and the other levels of the hierarchy. These roles enable data scientists with the ability to generate information from the data, as well as integrate advanced algorithms and system responses into the end-to-end data flow.
- Information Level and Knowledge Level: At this level, data scientist-type roles deploy algorithms on top of data flow pipelines to generate an enriched data context and statistical summary of the real-time data. A data operations engineer should work closely with a data scientist to enforce standardized means of deploying algorithms on top of the streaming data collection.
- Knowledge Level and Wisdom Level: The enriched data context of the knowledge level provides vital guidance to machine learning engineers to train and apply advanced machine learning models to the data collection. For example, training a system response to classify based on statistical thresholds, identified by data science, allows the model to be deployed in real-time to detect statistical outliers.
- Wisdom Level and Data Level: Artificial intelligence (AI) engineers are the primary roles that leverage machine learning solutions to create closed-loop systems in the software-defined context, and then take the necessary actions. This requires an understanding of the advanced machine learning models and how to perform real-time updates to essentially create negative feedback loops for automation, based on events identified in the end-to-end data flow. Additionally, AI engineers require close collaboration with data operations engineers to properly integrate closed-loop processes into the foundational code stack.
In a data-centric context, the data operations engineer role is arguably the most critical, yet often overlooked, skillset required to developing automated solutions of high value. Workshops should go over major functions and cross domain roles to help correlate dependencies on domain experts and AI engineers.
B. Data-Centric Architectures for Telemetry Analytics
A data-centric architecture treats data as a first-class citizen. In these types of architectures, all (or most) data is centralized through a common message queue that allows the incoming data to:
1) be standardized and contextualized,
2) route incoming data flow from data producers to their targeted data consumers, and
3) enable on-the-fly deployment and integration of advanced processes and algorithms, hence enabling the data-centric value pyramid (see Figure 2) in an applied context.
Key considerations need to be accounted for to ensure such an architecture is stable, performant, and leverages infrastructure that drives collaboration and transparency at all levels of development. A common data-centric architecture deployed to meet such considerations is known as a Lambda architecture [3], as shown in Figure 2. Variations and simplified architectures based on Lambda architecture exist, such as the Kappa architecture [4], but they tend to have similar application, advantages, and challenges.
Workshops should contrast pros and cons of similar architectures along the lines of:
1) fault tolerance,
2) scalability and reliability,
3) ease of integration,
4) stateful analytics, and
5) batch layer processing, among others.
Examples of Lambda architectures deployed as a central architecture in large-scale businesses and their data operations are discussed in references 5 and 6. The foundational concepts are discussed in the next section to develop similar types of architectures in an applied context.
III. Foundational Concepts and Analogies to Deploy Lambda Architectures
To successfully develop a streaming analytics architecture in a software-defined context, it is helpful to understand and apply analogous concepts used in applied electric circuit theory. These analogies provide a context and mindset for developing end-to-end data flow circuits with software-defined components rather than traditional physical electronic circuit components.
A. Distributed Message Bus: “Wire Kit”
A distributed message bus essentially operates as the “central nervous system” of the system to enforce a data-centric model and is at the heart of deploying an applied Lambda architecture. The bus enables integration of one-to-many applications required to deploy unique dataflows and analytics systems.
Apache Kafka, a consumer-centric, distributed message broker that uses an immutable commit log, supports such mass integrations and adheres well to requirements of the Lambda architecture [2]. Essentially, Apache Kafka provides the means to decouple data streams from each other (see Figure 3) and centralize stream processing on individual data flows [7–11].
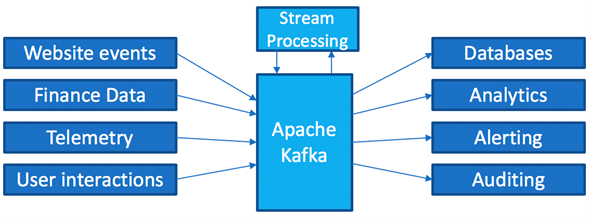 Figure 3: Decoupling Data Streams with Apache Kafka [8]
Figure 3: Decoupling Data Streams with Apache Kafka [8]
B. Containerization: “Integrated Circuit Packaging”
Containerization of subsystem components is used to test and deploy applications that operate as data sources and data sinks. These containerized subsystems are interfaced with other subsystems to launch specific data-flow contexts required to develop automation and intelligent cloud solutions. Docker is the primary tool used to containerize applications to be [12–16]:
- Flexible, lightweight, interchangeable, portable, scalable, and stackable
- Enabled for communication between multiple applications, both containerized and non-containerized
- Compatible to run on Linux, Windows, and MacOS
C. Container Management: “Breadboard”
Multi-container deployment management is used to configure, launch, and manage multiple containerized subsystems and services, such as with Kubernetes or Docker Compose [17–21]. Dataflows between cloud applications can be deployed and tested locally within the context of each required subsystem application programming interface (API), as well as enable “endpoints” to access each separate type of deployed service remotely. With container management, context-specific data streams can:
- Be prototyped in a single file that references all required Docker images
- Enable quick verification to ensure that all defined subsystems and services are properly configured to communicate between each other locally, as well as with other remote applications
- Link together and launch multiple applications built upon each other and other dependent services
D. Data Input/Output: “Pinout Specification”
Data input/output between services is accessed through each specific service application developer’s API, such as described in references 22 to 27. These APIs are referenced to understand how to access data from various cloud services, similar to referencing an electronic hardware component’s specification sheet.
E. Signal Definitions/Data Schemas: “Data Signal”
In a data-centric context, remote procedural call (RPC) schemas are used to define the data signal and the specific parameters to operate upon. Apache Avro type schemas [28, 29] in particular help enable and enforce the following within the bounds of a Lambda architecture:
- Data is strongly typed with support for: Primitive types, complex types, logical types, and data records
- Data is compressed automatically (less central processing unit [CPU])
- JavaScript object notation (JSON) defined schema is included with the data
- Documentation can be embedded in the schema
- Data can be read across any language (binary)
- Schemas can safely evolve over time
F. Data Schema Management & Registry: “Signal Domain”
A schema registry is used to manage defined data schemas and essentially create a “signal domain” to support many different data streams—all without breaking schema dependencies between data producers and data consumers [30-34]. If a data producing application releases a new version, changes to the API will likely take place, and the schema will have to be updated—which, traditionally, would break the system data flow to all dependencies. Therefore, a schema and a schema registry are critical components to deploy Lambda architectures.
G. Streaming Analytics & Dynamic Controllers: “Closed Loop Feedback”
Microservice applications are deployed to enable dynamic controllers and streaming analytics processors. Understanding control theory is central to understanding how to incorporate real-time streaming processes. Leveraging the extended Apache Kafka Streams API is an example of how the incorporation of closed-loop system deployments can be standardized and centralized to a streaming data platform [34–35]. With these foundational concepts and analogies in mind, the architecture and solution described in the following sections adopt a simplified deployment of the Lambda architecture, known as a Kappa architecture. In a Kappa architecture, only the streaming/speed layer is deployed in the architecture and all data is treated as streaming data [4].
In this context, the Apache Kafka ecosystem becomes a prime candidate to deploy such an architecture, as Kafka itself provides:
1) fault tolerance and high availability,
2) horizontal scaling,
3) ease of integration with many telemetry sources through the Confluent REST proxy and the Kafka Connect extended APIs,
4) stateful analytics, and
5) flattened batch data to streaming data, both achieved with the Kafka Streams extended API.
Based on meeting requirements of Lambda architecture and meeting data-centric requirements, the Apache Kafka ecosystem was selected at the center of our solution and approach.
IV. Network Traffic Analysis Using CLOS Data Center Network Architecture
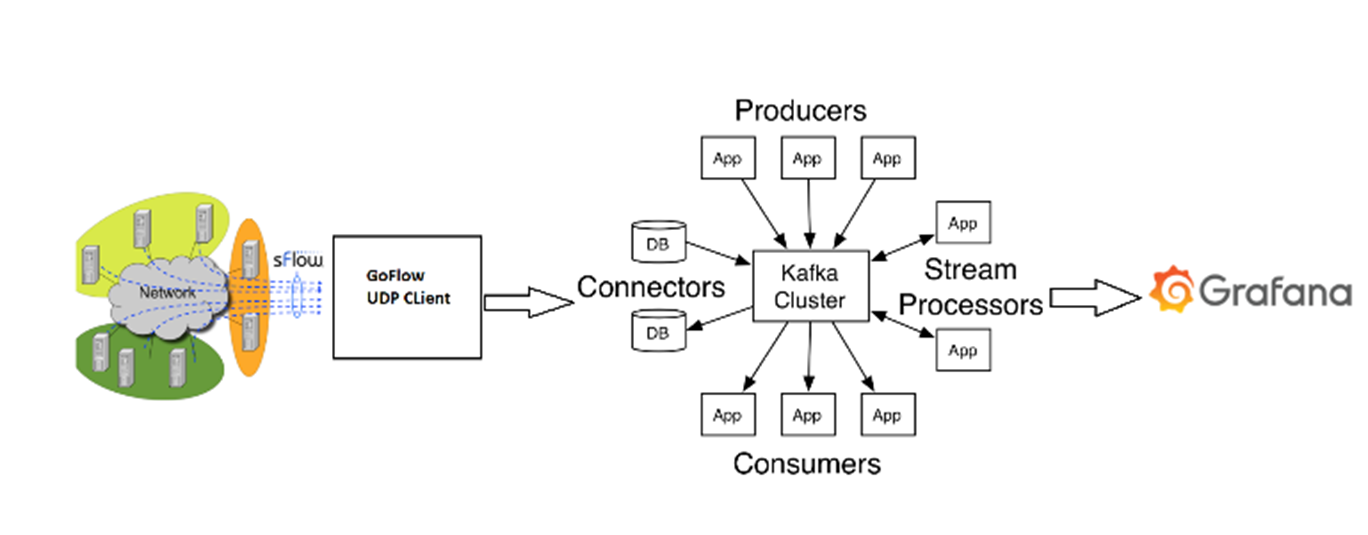
Figure 4: Test Bed Architecture
Workshops showcase real-world examples of Lambda architecture in a software-defined network context by leveraging one of the oldest DCN architectures and combining it with modern network traffic analysis frameworks. Our solution offers live traffic visualization and large flow detection in DCNs.
To achieve this, our test bed uses CLOS architecture. We enable sFlow agent on every switch in CLOS. sFlow agent is enabled to send all the samples collected to a centralized collector. GoFlow is our collector who receives the data and formats them into a Kafka input topic on brokers. Kafka streams read from this input topics and operate data science algorithms to identify:
- Switch paths utilized by the flows
- Large flows in the network
The output is visualized to the user in Grafana (Figure 5 shows our architecture).
A. CLOS Data Center Network Architecture
We use CLOS topology to run workloads on our servers. A CLOS topology is comprised of spine and leaf layers. Servers are connected to leaf switches (Top of Rack [TOR]) and each leaf is connected to all spines. There is no direct leaf-to-leaf and spine-to-spine connection. Here are a few architectural advantages of the topology:
- Regardless of being in the same virtual local area network (VLAN) condition, each server is three hops away from the others. That’s why this is called 3-5 stage CLOS topology. No matter how many stages there are, the total hop count will be the same between any two switches leading to consistent latency.
- Multi-chassis link aggregation group (MLAG, or MCLAG) is still available on the server side. Servers can be connected to two different leaf or TOR switches to have redundancy and load balancing capability. On the other hand, as the connectivity matrix is quite complex in this topology, failure can be handled gracefully. Even if two spine switches go down at the same time, connectivity remains consistent.
- The CLOS topology scales horizontally, which makes it easy to add more spine and leaf switches with increasing workloads.
B. sFlow & Packet Sampling
We use industry standard technology for sampling packets in high speed switched networks—sFlow. sFlow is enabled on all switches in the CLOS network and configured to send datagrams to a collector. sFlow is a multi-vendor sampling technology embedded within switches and routers. It provides the ability to continuously monitor application-level traffic flows at wire speed on all interfaces simultaneously. The sFlow Agent is a software process that runs as part of the network management software within a device (see Figure 5).
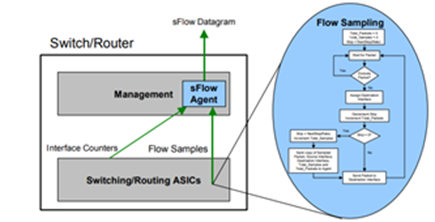 Figure 5: sFlow Sampling
Figure 5: sFlow Sampling
C. GoFlow: UDP Client from Cloudflare
All the data sampled from switches is then sent to a UDP agent, which converts sFlow datagrams to packet level records and produces the data into Kafka. This application is a NetFlow/IPFIX/sFlow collector in Go. It gathers network information (IP, interfaces, routers) from different flow protocols, serializes it in a protocol buffer (protobuf) format, and sends the messages to Kafka using Sarama’s library [36]. GoFlow is a wrapper of all the functions and chains them into producing bytes into Kafka.
D. Apache Kafka and Kafka Streams
We design and implement algorithms in Kafka Streams to analyze the packets and publish data. The algorithms are run with Kafka streams to:
- Create paths that all the flows took in DCNs, which consist of Spine and Leaf switches.
- Identify a large flow among many other flows in switches and create a notification on Grafana.
E. Grafana
Grafana is an open source, feature-rich metrics dashboard and graph editor for Graphite, Elasticsearch, OpenTSDB, Prometheus, and InfluxDB. We use Grafana for visualization purposes. All the data from Kafka is pushed into Grafana.
V. Testbed & Analysis
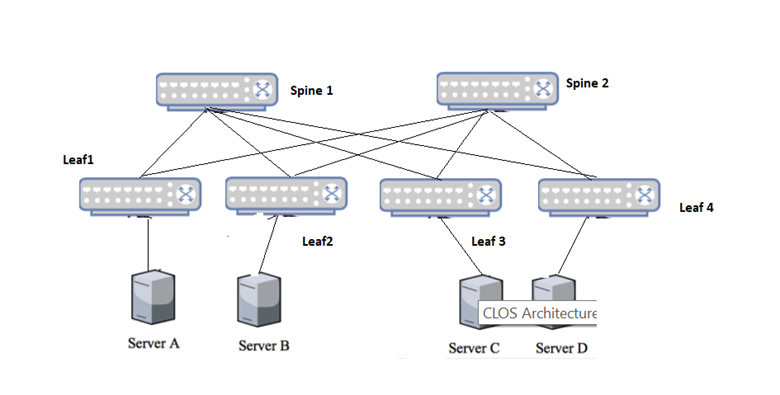 Figure 6: CLOS Test Bed
Figure 6: CLOS Test Bed
The testbed consists of two spine switches (Spine 1 and Spine 2), four leaf switches (Leaf1, Leaf2, Leaf3, Leaf4) and four hosts (Host1-Host4), as shown in Figure 6. Each leaf switch is connected to one host machine. Spine and leaf switches are connected in CLOS topology. Data from the testbed is centralized and integrated in a small production-grade Kafka cluster [37]. As shown in the simplified architecture of the Kafka cluster in Figure 7, the necessary infrastructure is in place to easily ingest, contextualize, and perform analytics on the streaming, real-time data being produced from the testbed. 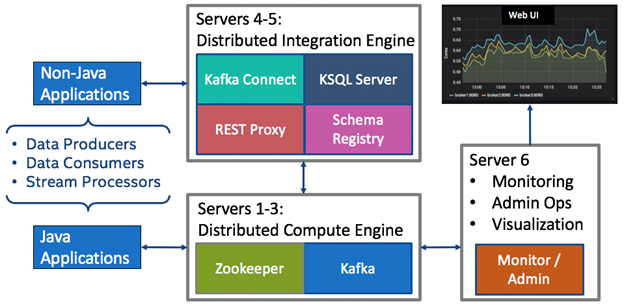
Figure 7: Simplified Architecture of Production Grade Kafka Cluster
The CLOS test bed shown in Figure 6 sends sampled data to the GoFlow UDP client, which is then relayed and produced into Kafka. The Kafka producer is written in Go-Lang, in which it provides a wrapped protocol to persist data directly into Kafka in an identical way to native Java applications. With a stream of live data from the test bed, our monitoring server can access the data stream and visualize it in real-time using the Grafana user interface (UI). Additionally, all data streams can be processed on for analytics using the Kafka Streams API.
A. Scenario 1: Identify Packet Path
Iperf sessions are established between server A and C. Output from the Kafka streaming application would be in the below format. Flow ID is the flow identification number, and Figure 8 lists the switches the flow went through. The output shows that the switch path that each flow took between servers is unique.
 Figure 8: Kafka Output
Figure 8: Kafka Output
B. Scenario 2: Large Flow Identification
In this scenario, multiple Iperf sessions are running between server and client. At any given time, the server is sending 100 flows to the client. Out of these flows, 2 to 3 are elephant flows. Elephant flows are defined as a flow that takes up more that 10% of the link bandwidth. Kafka streaming application identifies elephant flows among the flows and creates a notification on the new Kafka topic, as shown in Figure 9.
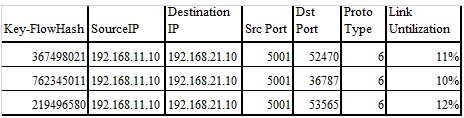 Figure 9: Example Notification
Figure 9: Example Notification
Editor’s Note: This article was originally written by Sunku Ranganath, Aaron Funk Taylor, and Sravanthi Tangeda. All rights reserved. A version of this article originally appeared in Medium.
This article is a product of the International Society of Automation (ISA) Smart Manufacturing & IIoT Division. If you are an ISA member and are interested in joining this division, please email info@isa.org.
References
[1] Mcleod, S. (2018). Maslow’s Hierarchy of Needs. [online] Simply Psychology. Available at: simplypsychology.org/maslow.html[Accessed 16 Feb. 2019].
[2] Rogati, M. (2017). The AI Hierarchy of Needs — Hacker Noon.[online] Hacker Noon. Available at: hackernoon.com/the-aihierarchy-of-needs- 18f111fcc007 [Accessed 16 Feb. 2019].
[3] Marz, N. and Warren, J. (2015). Big Data. Shelter Island, NY:Manning Publ.
[4] Milinda.pathirage.org. (2019). Kappa Architecture — Where EveryThing Is A Stream. [online] Available at:milinda.pathirage.org/kappa-architecture.com/ [Accessed 16 Feb.2019].
[5] Ciocca, S. (2017). How Does Spotify Know You So Well? — Member Feature Stories — Medium. [online] Medium. Available at:medium.com/s/story/spotifys-discover-weekly-how-machinelearning-finds-your-new-music-19a41ab76efe [Accessed 16 Feb. 2019].
[6] Wetzler, M. (2017). Architecture of Giants: Data Stacks at Facebook, Netflix, Airbnb, and Pinterest — Really Good Metrics. [online] Really Good Metrics. Available at: blog.keen.io/architecture-of-giants-data-stacks-at-facebooknetflix-airbnb-and-pinterest/ [Accessed 16 Feb. 2019].
[7] Apache Kafka. (2019). Apache Kafka. [online] Available at: kafka.apache.org/ [Accessed 15 Feb. 2019]. Maarek, S. (2019). Apache Kafka Series — Introduction to Apache Kafka™. [online] Udemy. Available at: udemy.com/apache-kafka/ [Accessed 15 Feb. 2019]. Confluent. (2019). What is Apache Kafka? | Confluent. [online]
[8] [9] Available at: confluent.io/what-is-apache-kafka/ [Accessed 15 Feb. 2019].
[10] Kozlovski, S. (2017). Thorough Introduction to Apache Kafka –
Hacker Noon. [online] Hacker Noon. Available at: hackernoon.com/thorough-introduction-to-apache-kafka-6fbf2989bbc1 [Accessed 15 Feb. 2019].
[11] Docs.confluent.io. (2019). Kafka Operations — Confluent Platform.
[online] Available at: docs.confluent.io/current/kafka/operations.html [Accessed 15 Feb. 2019].
[12] Docker.com. (2019). Why Docker. [online] Available at:www.docker.com/what-docker [Accessed 15 Feb. 2019].
[13] Hub.docker.com. (2019). Docker Hub. [online] Available at:hub.docker.com/ [Accessed 15 Feb. 2019].
[14] Tao W., and J. Lee (2018). Docker Crash Course for busy DevOpsand Developers. [online] Udemy. Available at:www.udemy.com/docker-tutorial-for-devops-run-dockercontainers/ [Accessed 15 Feb. 2019].
[15] Reeder, T. (2015). Why and How to Use Docker for Development – Travis on Docker — Medium. [online] Medium. Available at: medium.com/travis-on-docker/why-and-how-to-use-docker-fordevelopment-a156c1de3b24 [Accessed 15 Feb. 2019].
[16] Husain, H. (2017). How Docker Can Help You Become A More Effective Data Scientist. [online] Towards Data Science. Available at: towardsdatascience.com/how-docker-can-help-you-become-amore-effective-data-scientist-7fc048ef91d5 [Accessed 15 Feb. 2019].
[17] Kubernetes.io. (2019). Production-Grade Container Orchestration. [online] Available at: kubernetes.io/ [Accessed 15 Feb. 2019].
[18] Docker Documentation. (2019). Docker Compose. [online] Available at: docs.docker.com/compose/ [Accessed 15 Feb. 2019].
[19] Sanche, D. (2018). Kubernetes 101: Pods, Nodes, Containers, and Clusters. [online] Medium. Available at: medium.com/googlecloud/kubernetes-101-pods-nodes-containers-and-clustersc1509e409e16 [Accessed 15 Feb. 2019].
[20] Guminski, L. (2018). Orchestrate Containers for Development with
Docker Compose. [online] via @codeship. Available at: blog.codeship.com/orchestrate-containers-for-development-withdocker-compose/ [Accessed 15 Feb. 2019].
[21] Viaene, E. (2019). Learn DevOps: The Complete Kubernetes
Course | Udemy. [online] Udemy. Available at: www.udemy.com/learn-devops-the-complete-kubernetes-course/[Accessed 15 Feb. 2019].
[22] Matos, A., Verma, R. and Masne, S. (2019). What is REST — Learn
to create timeless RESTful APIs.. [online] Restfulapi.net. Available at:restfulapi.net/ [Accessed 16 Feb. 2019].
[23] Hacker Noon. (2019). What are Web APIs — Hacker Noon. [online]
Available at: hackernoon.com/what-are-web-apis-c74053fa4072 [Accessed 16 Feb. 2019].
[24] Developer.spotify.com. (2019). Web API Tutorial | Spotify for
Developers. [online] Available at: developer.spotify.com/documentation/web-api/quick-start/ [Accessed 16 Feb. 2019].
[25] Blockchain.info. (2019). Blockchain Data API — blockchain.info.
[online] Available at: blockchain.info/api/blockchain_api [Accessed 16 Feb. 2019].
[26] Developer.twitter.com. (2019). API reference index. [online]Available at: developer.twitter.com/en/docs/api-reference-index[Accessed 16 Feb. 2019].
[27] GitHub. (2019). Medium/medium-api-docs. [online] Available at:
github.com/Medium/medium-api-docs [Accessed 16 Feb. 2019].
[28] Avro.apache.org. (2019). Welcome to Apache Avro!. [online]Available at:avro.apache.org/ [Accessed 16 Feb. 2019].
[29] Maarek, S. (2017). Introduction to Schemas in Apache Kafka with
the Confluent Schema Registry. [online] Medium. Available at: medium.com/@stephane.maarek/introduction-to-schemas-inapache-kafka-with-the-confluent-schema-registry-3bf55e401321 [Accessed 15 Feb. 2019].
[30] Docs.confluent.io. (2019). Schema Registry — Confluent Platform.
[online] Available at: docs.confluent.io/current/schemaregistry/docs/index.html [Accessed 16 Feb. 2019].
[31] GitHub. (2019). confluentinc/schema-registry. [online] Available at:github.com/confluentinc/schema-registry [Accessed 16 Feb.2019].
[32] Maarek, S. (2017). How to use Apache Kafka to transform a batch
pipeline into a real-time one. [online] Medium. Available at: medium.com/@stephane.maarek/how-to-use-apache-kafka-totransform-a-batch-pipeline-into-a-real-time-one-831b48a6ad85 [Accessed 16 Feb. 2019].
[33] Maarek, S. (2019). Apache Kafka Series — Confluent Schema
Registry and REST Proxy. [online] Available at:udemy.com/confluent-schema-registry/ [Accessed 15 Feb. 2019].
[34] Medium. (2019). Using Kafka Streams API for predictive budgeting– Pinterest Engineering — Medium. [online] Available at:medium.com/@Pinterest_Engineering/using-kafka-streams-apifor-predictive-budgeting-9f58d206c996 [Accessed 16 Feb. 2019].
[35] Maarek, S. (2019). Apache Kafka Series — Kafka Streams For Data
Processing. [online] Udemy. Available at: udemy.com/kafkastreams/ [Accessed 16 Feb. 2019].
[36] Godoc.org (2019). Package Sarama. [online] Available atgodoc.org/github.com/Shopify/sarama [Accessed 28th Feb 2019].
[37] Shapira, G. (2016). Confluent Enterprise Reference Architecture.[online] Confluent. Available at:www.confluent.io/resources/apache-kafka-confluent-enterprisereference-architecture/ [Accessed 15 Feb. 2019]

