

Use Cases and Demos for Closing the Loop for Telco Services with Hardware Infrastructure
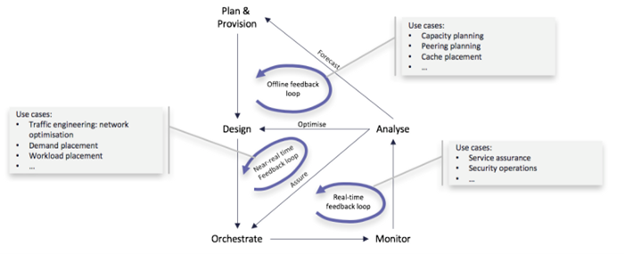 Figure 1: Various Feedback Loops in a Virtualized Network Infrastructure [2]
Figure 1: Various Feedback Loops in a Virtualized Network Infrastructure [2]
Abstract
Transformation of network softwarization towards 5G inherently requires satisfying the requirements across a broad scope of verticals like virtualized infrastructure, internet of things (IoT), edge computing, visual cloud, etc., while maintaining quality of service (QoS) and quality of experience (QoE) criteria required to satisfy service constraints, including latency. While individual aspects of telemetry, monitoring, service assurance, remote analytics, offline telemetry processing, observability, load balancing, etc., have always existed, there is an urgent need for ensuring these aspects work together across ETSI NFV [1] layers in a consistent, predictable, and automated way in order to provide true capabilities of scalable and resilient closed loop automation.
This blog shares various aspects of closed loop automation in 5G networks with emphasis on various closed loops possible and/or available and are common across various verticals. This blog also contextualizes telemetry and monitoring constraints, importance of closed loop across NFVI, common interfaces and APIs across MANO layer with reference to open-source initiatives across OPNFV and ONAP communities to help ease the adoption of 5G software.
I. INTRODUCTION
Network and infrastructure transformation to enable 5G require adoption of truly scalable and automated infrastructure that can be customized on demand. Closed loop automation intends to provide a simple and manageable way to automate network and virtualized infrastructure with the help of monitoring, analysis, dynamic orchestration, real-time infrastructure provisioning, etc. However, there are gaps across multiple layers and common interfaces yet to be established to satisfy various latency sensitivity requirements. This blog introduces various aspects of closed loop automation described across sections below, while engaging audiences on important use cases that can take immediate advantage of closed loop implementation using open-source software.
II. BUSINESS USE CASES
5G deployments across various services care about a common set of business use cases that form the backbone of service delivery. Communications service providers and operators care about ensuring certain service level agreements (SLAs) be met to ensure the level of availability required by specific slices. Closed loop automation needs to provide interfaces and corresponding interfaces to satisfy the relevant use cases and interfaces. The use cases that heavily rely on platform infrastructure could be broadly categorized as:
A. Improved & Consistent Customer Experience
Factors such as service-healing, self-healing networks, edge placement, service optimization, differentiated QoS, and latency sensitive resource optimization all play a crucial role in determining quality of customer experience. All these factors contribute to the end customer QoE and influence the level of QoS for the specific service provided by the network and network elements.
B. Cloud Optimization & Efficiency
The ability to provide dynamic resource provisioning, cloud configurations, high availability, service chaining, reliability, resiliency, and so on heavily impact SLAs.
C. Energy Efficiency & Power Management
Energy optimization, green deployments, power management, idle power optimization, performance per watt considerations, etc. have significant impact on operations expenditure.
D. Security
A fully autonomous network and infrastructure operations require security to be the backbone of deployments. There are multiple use cases such as threat detection, threat response, isolation, etc., that need to be considered as part of the implementation.
While these are just few of the business cases that can take advantage of closed loop automation, this blog intends to use these as a basis for providing constructs on building closed loop automation-based solutions. Remaining sections go through the various components required for building right closed loop solutions, current state, and innovation required to bring upon truly automated solutions.
III. CLOSED LOOPS
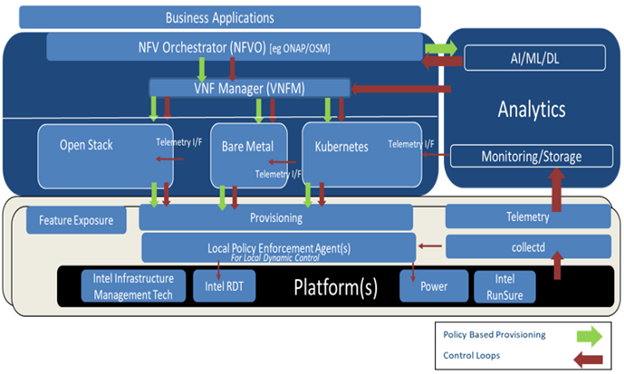 Figure 2: Mapping of Multiple Closed Loops across ETSI NFV Stack
Figure 2: Mapping of Multiple Closed Loops across ETSI NFV Stack
Closed loops by themselves can be constructed at various layers in the ETSI NFV stack. The task of implementing the closed loops that generally comes under Day 2 operations would need not just fall under network administrator, but it should be planned from planning and deployment stages of the infrastructure. As the author in [2] indicate the various feedback loops, as shown in Figure 1, different loops require individual level of planning, software interfaces, and implementations. Closed loops also include loops controlled by SDN controllers. As covered in [2], the article specifically focuses on the ETSI NFV scope and components required to interoperate to provide a system level approach with NFVI, VIM, and NFVO as the key focus.
Most brownfield deployments would have an either simple or complex set of existing offline feedback loop mechanisms in place [3] [4]. Orchestrators such as OpenStack and NFVO implementations such as ONAP & OSM have modules and interfaces in place to provide offline analysis and corresponding actions to the VNFM. However, significant challenges come into play in providing near real-time and real-time feedback loops. These types of loops require relevant interfaces across platform, telemetry collection, decision-making modules, and provisioning software. In a service provider environment, the real-time closed loops would need to consider millisecond latencies while near real-time closed loops would need to consider latencies around seconds’ timeframe. The infrastructure should allow the decision making to help re-provision the hardware resources within the said timeframe. This blog introduces the concept of local policy enforcement agent, as indicated in Figure 2, to help facilitate dynamic provisioning and resource management of latency sensitive hardware resources. Further details are discussed in Section VII.
The closed loops thus discussed play a crucial role in ensuring the network slices have the contextual service assurance and physical resources necessary for meeting SLAs [5]. The rest of the blog assumes the context provided could be directly applied to network slicing that is an essential backbone for 5G systems.
IV. TELEMETRY & MONITORING
Platform infrastructure across NFVI plays an important role in shaping the sensitivity of the closed loop in play. Monitoring and telemetry data from the right platform hardware interfaces are crucial to collect and expose it to north bound interfaces. Various aspects of telemetry collection across network, compute, storage, and virtualized elements of the platform, with concepts of push vs. pull of telemetry metrics, various software available for push model (Collectd, Telegraf), and pull models like Prometheus are important in a closed loop context. Telemetry collection models require configurations to customize them to be efficient at millisecond collection intervals while providing the abilities to manage the huge amount of Collectd data with relevant analytics models. Another aspect of importance is that of metrics tagging and labeling, in context of the work being done by OpenConfig [6].
Examples of various telemetry available from the infrastructure include, but are not limited to:
- Intel Resource Director Technology metrics that provides Last Level Cache and memory bandwidth utilization metrics
- Event-based metrics that monitors process starts and exits, monitor network interface ups/downs, etc.
- Data Plane Development Kit (DPDK) metrics and hugepage telemetry
- Virtual switching metrics via OpenVSwitch
- Out of Band telemetry using IPMI & RedFish plugins
- Hypervisor metrics including Libvirt metrics
- VNF Event Stream schema integration and telemetry consumption
- Flow metrics like IPFIX and sFlow
- Simple Network Management Protocol (SNMP) telemetry for traditional network equipment
- Platform metrics that exposes reliability, fault configurations, performance indicators, and so on
With the infrastructure evolution towards 5G, the monitoring systems should both be interoperable and support legacy systems while building on latest innovations in the streaming telemetry space [7].
V. MANO INTERFACES
The operator ecosystem is investing a good number of resources in enabling NFVO layers to be interoperable and adaptable to big data collected across clusters, cross-geo deployments, edge deployments, etc. By considering Open Network Automation Platform (ONAP) as an example, this blog shares various efforts and approaches taken by the operators and service assurance vendors to architect the right stack that helps provide the long-closed loop of offline processing. It’s important to note that this overarching closed loop, while providing insights into the overall operations of the operator environment, should also be complimentary and interoperable to various real-time or near real-time closed loops that leverage policy enforcement agents that are local to individual compute nodes, as indicated in Figure 2. This necessitates the fact that the centralized policy maker across NFVO should be extended to not just enforce a policy on a specific instance of VNFM, but extend and integrate with policy enforcers within the local cluster managed by VNFM and the policy agents on the computes nodes within the cluster. Another aspect to consider is the ongoing work in CLAMP [8] and distributed big data network analytics, and their integration into Artificial Intelligence (AI) platforms.
VI. ANALYTICS IN CLOSED LOOP
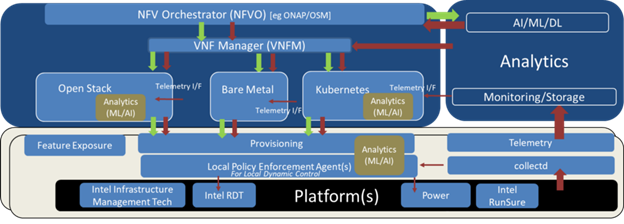 Figure 3: Application of Analytics for Various Closed Loops
Figure 3: Application of Analytics for Various Closed Loops
A truly autonomous network and infrastructure requires a level of intelligence and synthesis with capability to enforce the decisions taken. This requires the right level of telemetry to be consumed at node level for real-time closed loops, VNFM level for near-real time closed loops, and at NFVO level for overall processing, as indicated in Figure 3. While existing tools like Prometheus, with its integration into Collectd, provide relevant telemetry, there are still open items that are necessary to enable overall control of a Virtual Machine or a container to satisfy the SLA. The platform metrics and application metrics need to be correlated and tailored for a specific set of use cases based on the workload.
Some of the challenges here include, but are not limited to, metrics tagging, labeling, and correlating platform events with application changes, some of which are being discussed as part of OpenMetrics initiatives [9]. Analytics play an important role in data visualization, modeling, trending, and capacity optimization that are not often easy to correlate without an intelligent agent. The choice of the algorithm or the extent of intelligence would differ heavily based on the use case being chosen to be automated in a closed loop.
With the advent of streaming analytics, the complexity and requirements from monitoring agents increase yet again to be able to provide metrics with a relevant schema to perform necessary correlation on streaming data and write the recommendations to either a local policy enforcer or a central controller. The open-source projects Collectd, Kafka, KSQL, HDFS, etc. play important roles in enabling the Telecom cloud software stacks. Looking into the integration required for big data analytics and capabilities of frameworks like Acumos AI, Platform for Network Data Analytics (PNDA) provides the overarching context of overall closed loop in big-data scenarios.
VII. DYNAMIC INFRASTRUCTURE PROVISIONING
While the real-time and near real-time closed loops require the platform infrastructure to be intelligent to assign relevant resources to corresponding network slices, outsourcing the decision making to a remote node across the cluster or to a central node across NFVO heavily delays the decisions to be applied at the infrastructure level, thus hindering the real-time closed loops at the infrastructure level. This necessitates introducing node level local policy enforcement agents on every compute node that has hooks into platform telemetry, node level analytics agents, and enforcement interfaces into operating system or application workloads.
Multiple studies have been published to necessitate such actions on individual node to leverage latency sensitive hardware tuning and provisioning for technologies such as Intel Resource Director Technology that enables control of Last Level Cache on a CPU [10], Intel Speed Select Technology that enables adaptive frequency and power management for individual cores on a CPU [11], etc. See examples of local policy enforcement agents in reference to Resource Management Daemon (RMD) and Tuned that help provide required functionality to provision the said hardware resources to satisfy real-time constraints in [12] and [13].
VIII. DEMOS OF RELEVANT CLOSED LOOP USE CASES
This blog highlights two business use cases that can rely and take advantage of closed loop automation at the NFVI level:
A. Closed Loop Resiliency Demo
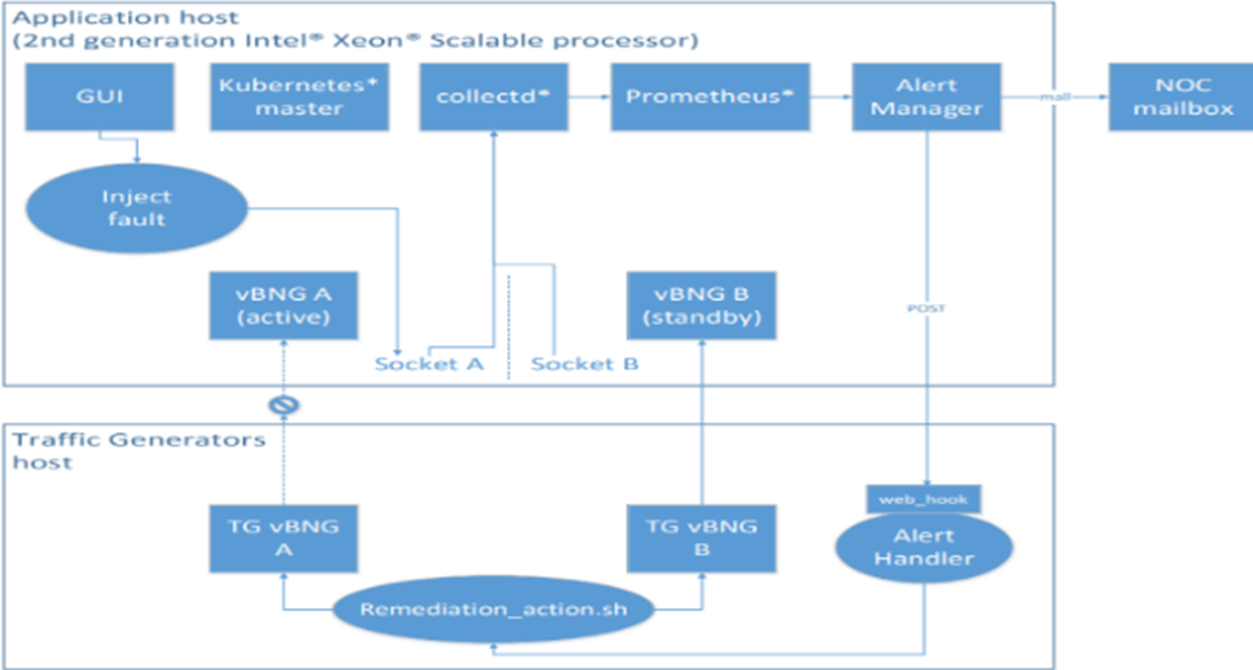
Figure 4: Closed Loop Resiliency Demo Topology with vBNG as the Workload
This demo leverages platform health metrics and reliability metrics from the Intel RunSure Technology Advanced Error Reporting (AER) subsystem [14] to notify the Prometheus alert manager and custom alert handler system to notify memory faults in a Kubernetes deployment on a single compute node. The demo utilizes a live Data Plane Development Kit (DPDK) based containerized Virtual Border Network Gateway (vBNG) application in an active-standby mode, processing live traffic from Traffic Generator (TG) across SR-IOV Virtual Functions and does fail over when a memory fault is injected artificially with full service recovery in a fully automated fashion, as indicated in Figure 4. Figure 5 indicates the graphical interface provided by the demo to show the resiliency demo using the Board Instrumentation Framework with vBNG as the Workload [15].
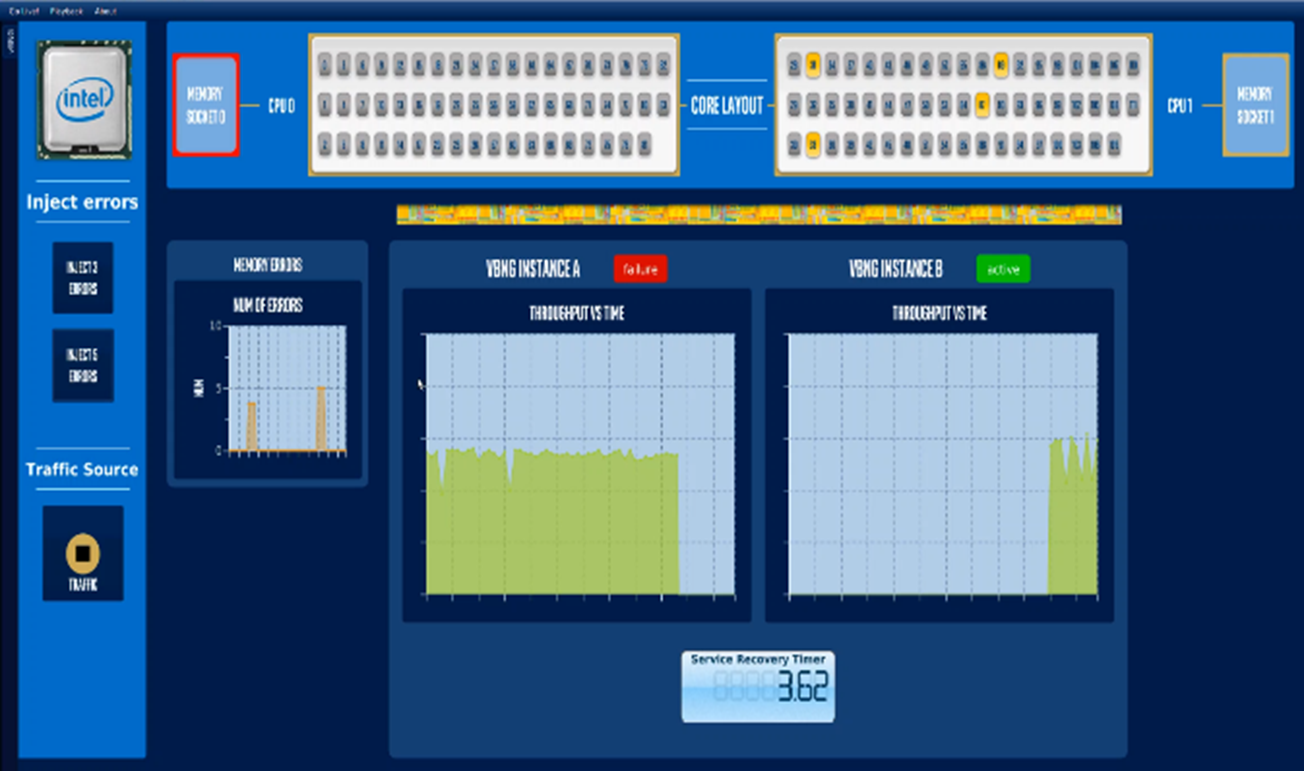 Figure 5: Graphical Interface of Closed Loop Resiliency Demo with Service Recovery Time
Figure 5: Graphical Interface of Closed Loop Resiliency Demo with Service Recovery Time
B. Closed Loop Automated Power Savings Demo
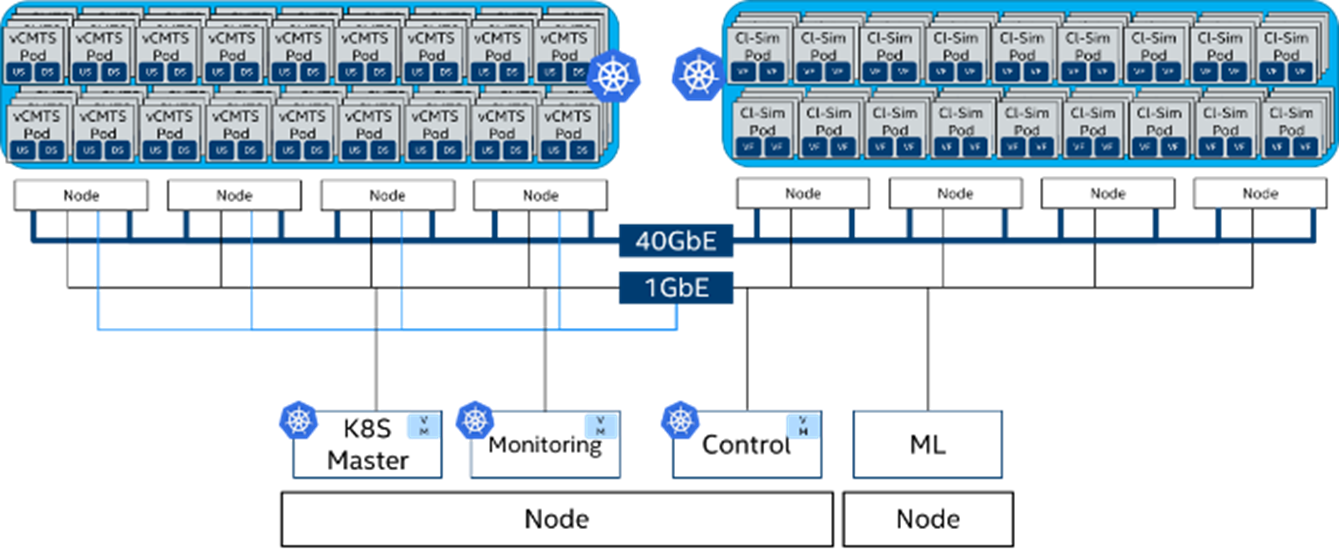
Figure 6: Demo Deployment Topology with vCMTS as the Workload
This demo showcases “intelligent” scaling of CPU core frequencies associated with a workload instance running in Kubernetes, based upon key performance indicators (KPIs) gathered via telemetry agent Collectd. The workload used in this demo is a sample application using DPDK that provides Virtual Cable Model Termination System (vCMTS). The topology is indicated in Figure 6. 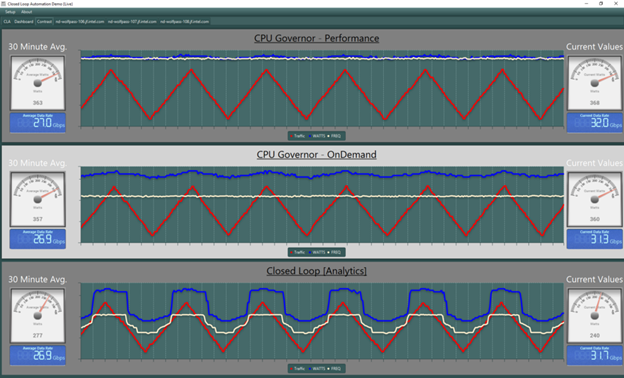
Figure 7: vCMTS Compute Node Power Savings of ~80–100W with Frequency Scaling
The core frequencies are scaled up or down based on bandwidth demand to achieve power savings. Overall, using the real-time closed loop automation at infrastructure level, the demo shows power utilization drop from 360 Watts with no frequency scaling to a total power utilization of 240 Watts as indicated in Figure 7. The demo would also go over correlation of CPU utilization and frequencies with CPU core thermal data and fan speed metrics and ability to detect/comprehend the platform based on this telemetry. 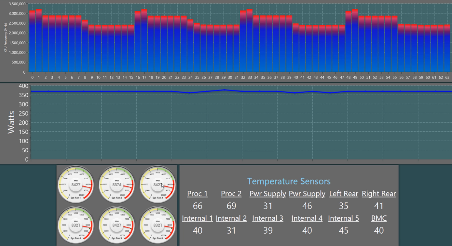
Figure 8: Thermal & Platform Sensor Metrics
IX. CHALLENGES & VIEW AHEAD
Although the industry is at a “walk” stage, there are quite a few challenges ahead to achieve a “run” stage in order to deploy a fully autonomous network. There are multiple initiatives across standard bodies like TMForum [16] and ETSI Zero Touch Network & Service Management (ZSM) that are working on standardizing the interfaces based on cloud native principles [17]. There is ongoing work in ONAP ecosystems making progress with overall closed loop implementation and the efforts in working group within the OPNFV community for infrastructure based closed loop [18].
Editor’s Note: This content was originally published and presented at IEEE 5G World Forum 2019 with the title “Closing the Loop with Infrastructure & Automation.” This article was originally written by Sunku Ranganath, John Browne, Patrick Kutch, and Krzysztof Kepka. All rights reserved. A version of this article originally appeared in Medium.
This article is a product of the International Society of Automation (ISA) Smart Manufacturing & IIoT Division. If you are an ISA member and are interested in joining this division, please email info@isa.org.
References
[1] Industry specification, European Telecom Standards Institute Network Function Virtualization reference architecture, etsi.org/technologies/nfv
[2] J. Evans, “Feedback Loops and Closed Loop Control”, Architecture Blogs, Platform for Network Data Analytics.
[3] NMS-2T20 Sessions, Networkers 2004, “Designing And Managing High Availability IP Networks”, cisco.com/c/dam/en/us/products/collateral/ios-nx-os-software/high
availability/prod_presentation0900aecd8031069b, Cisco Systems, 2004.
[4] RFC 7575, Internet Engineering Task Force, “Autonomic Networking: Definition and Goals”.
[5] G. Brown, Teoco, “Contextual Service Assurance in 5G: New Requirements, New Opportunities”.
[6] OpenConfig, openconfig.net.
[7] Application Note, “Collecting & Monitoring Platform & Container Telemetry”, Intel Network Builders,networkbuilders.intel.com/docs/collecting-and-montioring-platformand-container-telemetry-app-note.
[8] Wiki, Control Loop Automation Management,wiki.onap.org/display/DW/CLAMP+Project.
[9] K. Evans, blog, “CNCF to Host OpenMetrics in the Sandbox”, CloudNative Computing Foundation.
[10] J. Gasparakis, S. Ranganath, E. Verplanke, P. Autee, “Deterministic Network Functions Virtualization with Intel Resource Director Technology”
[11] Application Note, Intel Speed Select Technology — Based Frequency –Enhancing Performance”, Intel Network Builders.
[12] Github, documentation, github.com/intel/rmd.
[13] W. Boessenkool, RedHat, “Tuning Your System with Tuned”.
[14] Intel Developer Zone, “Delivering Intel Run Sure Technology with Intel Xeon Processor Family”.
[15] Github, “Board Instrumentation Framework”, github.com/intel/BoardInstrumentation-Framework
[16] Catalyst Project, TMForum, “5G Intelligent Service Operations”.
[17] Industry Specification Group Zero Touch Network Service Management, ETSI, etsi.org/technologies/zero-touch-network-service-management
[18] Wiki, “Closed Loop Platform Automation with OPNFV”, Open Platform for NFV.

