

This post was authored by Sanat Joshi, general manager of global automotive and manufacturing industries at Amazon Web Services.
We have all read and heard the stories in the media, including mainstream business publications such as The Wall Street Journal and The New York Times, about how big data is transforming business, saving money for companies, and finding them new revenue opportunities, all through insights gleaned from data. So we have all heard the term big data, but what does it actually mean?
No longer just the realm of Google, Facebook, and Amazon, big data is the new norm for enterprise analytics and is pervasive across many industries: drug discoveries enabled by genomic research, real-time consumer sentiment, and social interaction for retail represent a small sample of business innovation derived from big data technologies and analytics. Whether it is fine-tuning supply chains, monitoring shop floor operations, gauging consumer sentiment, or any number of other large-scale analytic challenges, big data promises to make a tremendous impact on the manufacturing enterprise.
A simple definition would be that data becomes big data, or rather a big data problem, when the volume, velocity, and/or variety of the data exceeds the abilities of your current IT systems to ingest, store, analyze, or otherwise process it.
Volume: There are many examples of companies dealing with very large volumes of data. Consider, for example, Google’s support of 1.2 billion searches a day; the huge number of users registered and posting on Facebook; oil field seismic surveys that are terabytes in size range; or the large number of financial transactions a big bank system might process every day. In the future, these data volumes are bound to grow exponentially, as the “Internet of Things” becomes a reality, with some analysts predicting the number of Internet-connected devices to grow to 24 billion devices by the year 2020.
Variety: Traditionally, data managed by enterprises was mainly limited to structured data, i.e., the format of the data was well-defined, making it relatively simple to categorize, search, and analyze the data. However, what happens when the data is messy, such as data from a blog, or Twitter feeds, or data collected from a seismic survey of an oil field, or event data collected from millions of sensors embedded in an electrical network, or even text descriptions in emails sent to customer service? Would it not be valuable to be able to mine these unstructured data stores to identify patterns and search for meaningful themes?
Velocity: As embedded sensors in all sorts of equipment become ubiquitous, and the cost of mobile connectivity continues to drop, we can expect the speed at which data is collected to go up exponentially. For example, imagine every car sold by a car company sending frequent updates about the health of various sub-systems in the car, and millions of cars on the road continuously sending in updates; or an oil-drilling platform receiving continuous streams of data from the well; or the click-stream data for users of an application like Facebook.

It is easy to see how this simple definition of big data hints at some not-so-simple challenges. Certainly, there are solutions for handling large quantities of data. Networking and bus technologies provide a transport mechanism for moving data rapidly. But what happens when that data is a mix of structured and unstructured data that does not fit neatly into rows and columns, AND it is high volume, AND it needs to be processed quickly? Think of data from millions of sensors on electricity networks or manufacturing lines or oil rigs. Identifying deviations from past trends in this data (and whether the deviations are “safe” or “unsafe”) in real time can help avoid a power outage, reduce waste and defects, or even avoid a catastrophic oil spill. This type of problem can be found in almost all industries today. The volume of data is growing too fast for traditional analytics because the data is becoming richer (each element is larger or more varied), more granular (time intervals decreasing from months to days or days to minutes), or just needs to be processed much faster than it used to.
So we need tools to collect and store these massive volumes of data, analyze the data to find meaningful patterns and relationships, make predictions, and thus make the enterprise smarter through business insights mined from this deluge of data. That is the challenge of big data.
Big data: The technology
There are a large number of technologies, tools, and techniques that are discussed under the term big data, such as predictive analytics, data mining, Hadoop (open-source software framework that supports data-intensive distributed applications), pattern detection, statistical modeling, sentiment analysis, market-basket analysis, etc. Where do these technologies fit in?
It is probably more useful to think about big data as an architectural approach where movement of massive amounts of data is minimized, there is no dependency on having to create data models in advance of data being gathered, and massive amounts of data can be analyzed and classified quickly to answer questions, and identify causal factors predicting business outcomes, such as a customer's likelihood of defecting, or the likelihood of a part failure.
Traditional architectures for data analysis rely on a data warehouse approach. Data is extracted from multiple sources, such as transactional applications like financial management systems or human resources databases. Next, data is transformed to fit a particular data model and then loaded into a data warehouse, which has a specific data model. The data model is created to make it easy to answer certain questions, such as providing a sales forecast or showing inventory levels or the number of warranty claims reported. Data generally need to be moved to another specialized server for performing statistical analysis. Making all these copies of data from the OLTP systems to data warehouses to reporting to statistical analysis systems is a costly and effort-intensive process that requires specialized expertise and prevents wide usage.
While these architectures are certainly valuable for reporting and analysis of structured data, they are not very efficient or do not work when it comes to dealing with the challenges of volumes, complexity, and variety created by big data.
A "best practices" approach to big data consists of a closed-loop process, involving three distinct phases: Big data management, information discovery, modeling and advanced analytics, and business model deployment.
Big data management
The first challenge of big data is efficiently acquiring and storing the petabytes of data, without having to create data models, and making it possible to easily perform operations such as grouping, aggregation, classification, and filtering of millions of rows of data.
Big data technologies, such as Hadoop, solve the problem of efficiently storing, managing, and analyzing almost unlimited amounts of information being generated at extremely high velocities. Some examples are data being generated by websites and event data being generated by sensors. These technologies leverage massively parallel software architectures and cheap computing power.
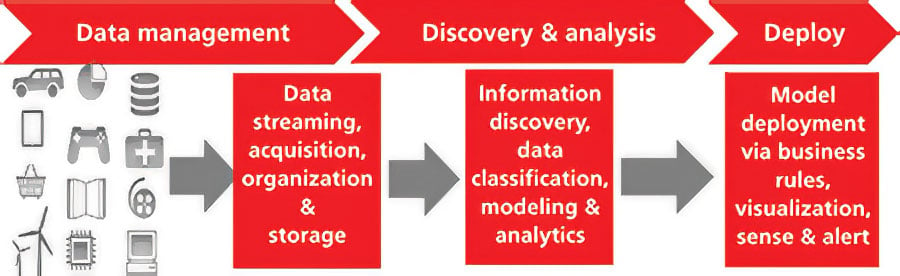
In many cases, you do not really know what patterns you are looking for, or what questions to ask. For example, a quality analyst may be looking at product quality data for parts that failed and to try to identify root cause. A process of exploration and discovery of the data is required. Because the actual relationships between different attributes are not always known in advance, uncovering insights is an iterative process to find the answers.Information discovery, modeling, and advanced analytics
This iterative information discovery is made possible by capabilities, such as faceted search, data discovery using guided navigation of automatically identified attributes, and the ability to analyze both structured and unstructured data. Advanced visualization techniques like automatic tag clouds make up the information discovery phase. Where big data comes in is the speed of performing rapid information discovery with vast amounts of structured and unstructured data that may not necessarily conform to a data model and may have been acquired from a variety of data sources.
Next, tools are provided for building models that can predict the likelihood of certain outcomes using statistical analytics methods. This is where predictive models are created and tested for fit against the data using techniques, such as clustering, regressions, decision trees, classification, prediction, and neural networks. Typically, a business analyst works with a data scientist to develop models that could help in understanding reasons, patterns, or causes behind the problem, identify ways of solving it, and predict future behaviors/outcomes.
Business model deployment
Once models have been developed that predict certain outcomes, such as the likelihood for a customer to defect to a competitor, or the likelihood for a part to fail, the models are deployed so that new data streams can be continuously evaluated against the model.
This is the step that converts data into information, and information into valuable insights.
Big data use cases
Use cases across different industries demonstrate the value and transformation possibilities of big data.
In the retail industry, big data is being used for improving profitability by optimizing segment and sentiment analysis by leveraging click-stream data, market-basket analysis, and data collected from social media sites. Financial institutions are using big data for fraud detection. E-commerce retailers and companies, such as Netflix and Amazon, use big data for recommending new products and services to their customers, based on past behavior, preferences, and purchasing patterns. Consumer packaged goods (CPG) companies use big data to predict and optimize how coupons and incentive promotions will affect sales of their products. Cell phone and cable television providers use big data to predict customer churn, i.e., what customers are likely to defect to a competitor.
In the manufacturing industry, big data has the potential to transform the industry through a variety of applications.
Manufacturing shop floor operations
Modern manufacturing shop floors are highly automated. Automation systems and controllers throw off large amounts of data, making the shop floor data an ideal environment to leverage big data. Although modern controllers generally conform to standards, such as ISA-95, for the data they generate, there is still heterogeneity of data formats in the data collected from various automation systems.
Imagine a manufacturing operation that has multiple makes of computer numerical control (CNC) and automation control systems, all generating data in a variety of formats, not necessarily conforming to any standard.
Data in significant volumes is being generated by these automation devices, such as status code and operation rates. Data from different manufacturing systems, such as process historians, manufacturing execution systems (MES), quality systems, and enterprise resource planning (ERP) systems, does not conform to any single data model, and technology differences make it difficult to bring together data from a variety of sources and put the data in context to answer questions "from the top floor to the shop floor." So while manufacturing operations generate massive amounts of data, much of it is unused or discarded.
Big data enables efficiently creating "mash-ups" of data from all these systems to answer specific questions, e.g., what was happening in the various automation systems when a certain manufacturing defect occurred; or tracing all the parts made that could be affected by a machine that was out of tolerance, or how an out-of-tolerance condition in a particular manufacturing cell would affect customer orders. Big data allows answering seemingly simple questions, such as "count how many times a certain machine breached a threshold," that otherwise could not have been answered quickly or easily in the past.
Manufacturers are beginning to report substantial cost savings or new revenues resulting from big data insights. A leading chip manufacturing company pulls logs from their chip manufacturing automation controls, which can be up to five terabytes per hour. By using big data analytics, the chip manufacturer can identify which specific steps in one of their manufacturing processes deviate from normal tolerances. This early detection can save entire batches from being rejected.
This same manufacturer also runs tests on pre-production chips and analyzes the data. By using predictive analytics, they are able to reduce the number of tests they have to run during the production process, thus saving millions of dollars in manufacturing costs for just one product line.
A leading car company is testing the use of data generated in their manufacturing operation in conjunction with sensor data collected from their cars to correlate manufacturing tolerance deviations with how the components perform. The same car company is benchmarking their best manufacturing operations in order to create a profile that can be used to improve all the other manufacturing operations to the same level.
Another automotive manufacturer needed to defend itself against devastating claims for unintended acceleration. They were able to combine data from 20 different sources, such as component manufacturing data at the machine level, assembly line data, parts testing data, warranty claims data, text data for complaints, and service data. Traditional techniques could have taken up to a year to sift through all the data; however, the use of big data technology made it possible to prove that there was no electronics-based acceleration issue.
The manufacturing use cases generally can be grouped into four categories:
- Predictive diagnostics for product/part failure: Understanding product quality issues and responding to them proactively remains one of the most significant challenges in manufacturing. Big data can help by efficiently identifying possible patterns in product quality data, manufacturing data, warranty claims, service reports, and usage data about products.
- Manufacturing data mining: The ability to mine vast amounts of machine data put out by automation systems on manufacturing plant floors will make big data very valuable. Looking at causal factors for quality issues, process variability, and traceability of parts through the manufacturing process are some of the use cases being tried in manufacturing.
- Warranty analysis: Warranty costs are a significant cost reserve item for manufacturers. Big data has been proven to significantly reduce warranty costs through identification of discrepancies in warranty claims either due to invalid claims, inadequate technician training, warranty fraud issues, or early warning of part failure.
- Remote intelligent services: As embedded sensors in all types of products become more prevalent, and as granular product usage data will become available, the ability of big data technology to detect event patterns will become critical. Imagine being able to detect and solve a potential problem - before the customer actually encounters it!
Organizations in every industry are trying to make sense of the massive influx of big data, as well as develop analytic platforms that can synthesize traditional structured data with semi-structured and unstructured sources of information. Big data can provide valuable insights into market trends, equipment failures, buying patterns, maintenance cycles, and many other business issues, lowering costs and enabling more targeted business decisions. For manufacturing companies, big data can be especially valuable through early detection of quality problems, reducing warranty costs, optimizing manufacturing processes, and providing the ability to fundamentally transform customer service through being able to respond to sensor data generated by customer field assets.
About the Author
Sanat Joshi, is general manager of global automotive and manufacturing industries at Amazon Web Services. Amazon is working with leading automotive companies to enable their connected vehicle and autonomous vehicle strategies, and helping them accelerate their digital transformation journeys. Prior to Amazon Web Services, Sanat led the automotive and manufacturing industry verticals at Oracle Corporation. Sanat’s areas of expertise include developing IT transformation strategies for global corporations, helping OEMs develop automotive connected vehicle strategies, and working with Fortune 500 companies on their digital transformation initiatives. Sanat has an MBA from the University of Michigan, Ross School of Business and an undergraduate degree in electrical engineering from the University of Pune.
Connect with Sanat![]()
A version of this article also was published at InTech magazine.
