

We learn by interacting with our environment—this is probably the first idea that occurs to most of us when we start to consider how people learn. In machine learning, reinforcement learning mimics the trial-and-error learning method of humans. The algorithms learn and improve over time by interacting with the environment and taking random actions.
But how do the algorithms know whether the actions taken in their present state were desirable? That’s where a scalar quantity known as rewards comes into the picture. Rewards are the environmental feedback from where our learning agent is functioning. Reinforcement learning is based on the reward hypothesis, which states that "all goals can be described by the maximization of expected cumulative reward."

Types of machine learning paradigms. Diagram courtesy of KDnuggets.
In the discipline of machine learning, reinforcement learning has shown the most promise, growth, and variety of applications in recent years. Autonomous helicopter control using Reinforcement Learning (Andrew Ng, et al.)1 and Playing Atari with Deep Reinforcement Learning (Deepmind)2 have achieved control much better than humans. Reinforcement Learning for Humanoid Robotics (Jan Peters, Sethu Vijayakumar, Stefan Schaal)3 displays how a robot learns to walk. This method has been proven to be far superior to state-of-the-art methods like non-linear control and path planning.
An environment in a reinforcement learning paradigm is anything with which an agent interacts or anything an agent observes. The environment is either fully observable by the agent or partially observable. In most cases, the dynamics of the environment are unknown, i.e., how the environment affects the agent when it takes an action. In these cases, the state of the agent cannot be anticipated just by the virtue of the action taken by it. The major advantage of reinforcement learning paradigms is their ability to learn the dynamics of the environment by interacting with it over time.
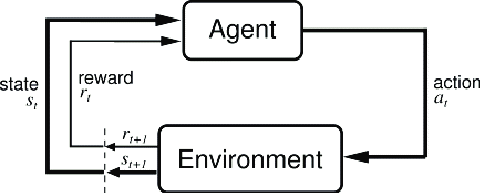
Agent/environment interaction. Diagram courtesy of ResearchGate.
For simplicity, consider a rover in a Martian environment. The rover is our agent and the rugged topography of Mars is our environment. The rover initially has no idea as to how the topography will affect its traversal. It could cause the wheels to slip, or the environment could introduce huge noise in the sensor values. So, can the rover incorporate these uncertainties? Yes! By interacting with the environment and learning more about it, using what are known as model-free reinforcement learning algorithms.
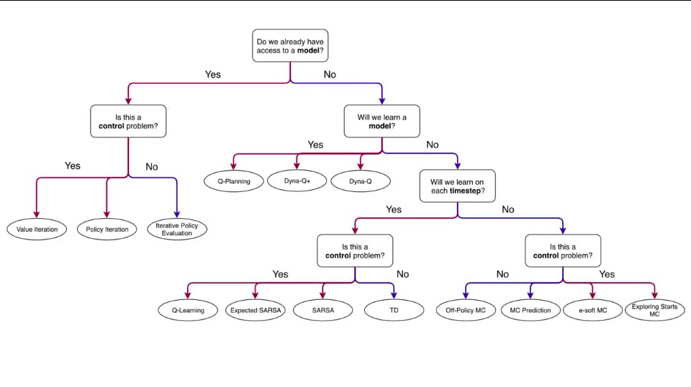
Methodology to choose a reinforcement learning algorithm. Diagram courtesy of the author.
One of the most notable and evolving applications of reinforcement learning is in autonomous navigation.
Autonomous navigation includes the following tasks:
- SLAM (simultaneous localization and mapping), which is the perception system of the robot
- Global and local path planning
- Reaching the destination whilst avoiding stationary and non-stationary obstacles
Here, the observation space typically consists of an IMU, a laser scanner (lidar) or stereo camera (depth camera), or both in conjunction to construct a map of the surrounding. The most common methods are Hector SLAM, cartographer, G mapping, and so on. The action space would typically consist of all the possible directions the bot can move in, and it would depend greatly upon the type of robot (holonomic or non-holonomic).
What makes reinforcement learning this applicative in robotics is its extension to continuous action spaces. The action space need not be discrete, i.e., the number of actions can be finitely many or infinitely many. State-of-the-art reinforcement learning algorithms allow the action space to be continuous while not compromising the real-time implications.
Rewards are the most important aspect determining how an algorithm behaves. Jona´s Kulh ˇ anek, Tim de Bruin, et al.4 coined the rewards to be a positive scalar for reaching the destination and zero for all other cases. Hartmut Surmann, Christian Jestel, Robin Marchel, Franziska Musberg, Houssem Elhadj, and Mahbube Ardani5 tuned the reward as follows:
- If the distance to the goal is smaller than before, the robot gets a small positive reward; otherwise, a small negative reward
- If the orientation of the robot is closer to the direction of the goal, it gets a small positive reward; otherwise, a small negative reward—often a negative reward is also chosen for each time step
Deep reinforcement learning paradigms show great promise for developing navigation stacks in uncertain stochastic environments. They help resolve issues like sensor noise and generate optimal steering policies. Ongoing research also includes integrating navigation control using wheel odometry rather than visual odometry where deep reinforcement learning is used to incorporate wheel slip in navigation predictions.
References
1 Andrew Y. Ng,* H. Jin Kim, Michael I. Jordan, and Shankar Sastry, Autonomous helicopter flight via reinforcement learning (https://people.eecs.berkeley.edu/~jordan/papers/ng-etal03.pdf)
*Video demonstration: http://heli.stanford.edu/
2 Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller, Playing Atari with Deep Reinforcement Learning
(https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf)
3 Jan Peters, Sethu Vijayakumar, Stefan Schaal, Reinforcement Learning for Humanoid Robotics
(https://www.cc.gatech.edu/~isbell/reading/papers/peters-ICHR2003.pdf)
4 Jona´s Kulh ˇ anek, Tim de Bruin et al, Vision-based Navigation Using Deep Reinforcement Learning (https://arxiv.org/pdf/1908.03627.pdf)
5 Hartmut Surmann, Christian Jestel, Robin Marchel, Franziska Musberg, Houssem Elhadj and Mahbube Ardani, Deep Reinforcement learning for real autonomous mobile robot navigation in indoor environments (https://arxiv.org/pdf/2005.13857.pdf)
Interested in reading more articles like this? Subscribe to ISA Interchange and receive weekly emails with links to our latest interviews, news, thought leadership, tips, and more from the automation industry.

